


One data structure that's often used in conjunction with files, called a cache, is a set of memory buffers that hold copies of file-based objects. Since reading from and writing to files is a relatively slow process, caches are used to enhance performance. Rather than fetching objects from the file every time they are needed, the copies kept in memory are accessed instead.
In this chapter, you'll see a unique cache design invented by the author. By using smart pointers called cached-object pointers (or Coptrs, pronounced as cop-ters), you can work with file-based objects with a pointer syntax that's similar to what you normally use for objects in memory. As you use Coptrs, the objects being referenced are stored and fetched to and from a file by way of a cache--almost transparently behind the scenes.
Persistent objects, which can save their state between program invocations, are currently a popular OOP topic. The file-based objects presented here are a weak form of persistent objects. Our file-based objects don't have the full capabilities of normal objects, lacking the ability to have pointers, destructors, and virtual functions. These file-based objects can, however, have constructors. In fact, you can construct file-based objects using an overloaded new operator with a syntax very close to that used for normal objects.
Even though our file-based objects aren't full objects, they are still quite useful for database applications. For example, you'll see how to use file-based objects to implement binary search trees that reside on disk. In fact, the material in this chapter lays the groundwork for Chapter 14, where we implement file-based B-trees.
At the heart of our file-based object design is the following Fmgr class (and associated data structures) that manages objects stored in files:
Unfortunately, we don't have space to explain all the design details of the Fmgr class. Instead, we'll provide a high-level description of how the class works. As always, the class is fully documented on disk. Keep in mind that the Fmgr class was painstakingly designed to be as versatile and efficient as possible.
Complete code for the Fmgr class is given on disk in the files fmgr.h and fmgr.cpp. The sample program about to be shown is given in the file fmgrtst.cpp.
The Fmgr class is the file-based equivalent of a heap manager. It has two functions, Alloc( ) and Free( ), which are analogous to the C functions malloc( ) and free( ). In addition, the Fmgr class has Fetch( ) and Store( ) functions that let you read and write objects. This example creates an Fmgr file and stores a Part object in it:
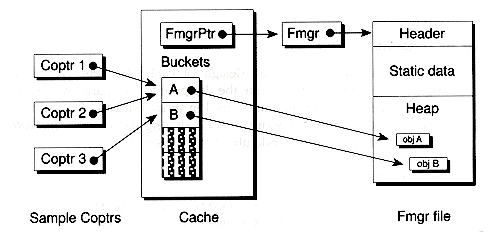
Fmgr files are reference counted to help detect synchronization problems when closing files. For instance, you may have several caches connected to the same file. By using smart pointers, we can disconnect the caches in any order. The file can only be closed when the last cache is disconnected. In the class definition, you'll notice that Fmgr is derived from the CountedObj class we gave in Chapter 5. You access Fmgr files through FmgrPtr objects, which are smart pointers defined as SmartPtr<Fmgr> types. As with all SmartPtrs, the reference counted object (in this case an Fmgr object) must be allocated dynamically.
The Fmgr class is fairly sophisticated, but it's still a low-level design. For example, although Fmgr will allocate objects for you, it doesn't keep track of their locations. Note how we kept the address of the Part in the addr variable. This is akin to allocating an object in memory and then recording its address in a pointer.
Further evidence of the low-level nature of Fmgr can be found in functions like Alloc( ), Fetch( ), Store( ), and Free( ), which must be told the size of the objects being used. Also, Fetch( ) and Store( ) use void pointers to pass the object data. We could derive template-based classes from Fmgr to serve as high-level type-casting interfaces. In fact, we showed an example of this in the RecFile and FileOf classes in Chapter 3. In this chapter, we'll show an alternative technique. The type-casting will be encapsulated in pointers, with a different pointer type for each type of object. Before we discuss these pointers, we'll review the layout of Fmgr-based files.
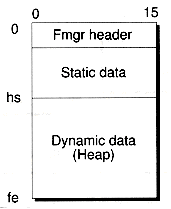
All Fmgr files have the same layout, being composed of three parts, (as illustrated in Figure 13.1): a header, a static data area, and a dynamic data area. The header is composed of four fields, as shown in Figure 13.2. The first three are used by the allocation routines (which we'll describe shortly). The fourth field is a four-byte signature of FMGR.. This signature is used by the Open( ) routine to determine whether a file is indeed an Fmgr-based file. Note that, while the file is open, the file header is also stored in memory using the FmgrHeader object h.
Following the header is a static data area, whose size is specified by the creator of the file. This area is analogous to the static data segment of your program, and can be used to store objects whose locations should be fixed. The static area is a good place to store small indices. For example, we'll store addresses to the roots of trees at known locations in the static area, so that we can easily find the roots.
The dynamic data area is analogous to a heap residing in memory. It starts out empty and grows when objects are allocated. The end of the heap is always the end of the file. Thus, the file grows as the heap grows.
The header fields hs, fe, and fs are used to maintain the heap. The hs field stores the address of the start of the heap. This field is used when the first object is allocated. Initially, hs points to the end of the static area, whose location is also stored in fe. As the heap grows, fe is adjusted to point to the end of the file, and represents the location where the file can be extended again, if necessary. Figure 13.3 shows how an object is added to an empty heap.
The fe field isn't strictly necessary because the end of the file could always be found by asking the operating system for the file size. However, keeping track of the end of the file ourselves is more efficient and can be used to make file integrity checks. For instance, if fe is tested and found not to be the size of the file, we know the file has been corrupted.
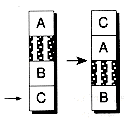
Objects are de-allocated by placing them on the free space list. This list is not unlike the free lists we used with linked lists in Chapter 8. The start of the free space is stored in the fs field. This field is initially zero. When an object is freed, its block of data is placed on the free list. The first portion of the block is overwritten with a free block header, as illustrated in Figure 13.4. This header holds a check word (given an arbitrary value of 0xfefe), the length of the block (not including the header itself), and a long integer giving the address of the next free block. This latter field is null when the block's at the end of the list.
Figure 13.5 shows the layout of a file with two of its four objects (object 1 and object 3) freed and placed on the free list. In this figure, object 1 was freed first, and object 3 freed last. Note that freed objects are always added to the front of the list and that the list is null terminated.
When a new object is to be allocated and the free list isn't empty (that is, fs isn't zero), then the list is walked, looking for a block of an appropriate size. The block must either be equal to the size of the object or greater than the size of the object plus the size of the free block header. The block is split in two--one part for the object and the other part to be placed on the free list again. The address of the first part is returned to become the address of the object. Note that no data is written to the block at this time. As far as the file is concerned, the object stays uninitialized until we write to its location.
The strategy we use for finding an appropriate free block is called the first-fit strategy because we scan down the free list until we find the first block the object will fit into. We may have to scan down the entire list, which can be quite long. And even then, there's no guarantee we'll find a good block. If we don't, then the file is extended to accomodate the new object and the fe field is adjusted accordingly.
We could use other, more sophisticated strategies. For instance, we could keep the list sorted in some way to shorten the time spent searching for a good block to use. We use the first-fit strategy because it's the simplest. Fortunately, when all the objects tend to be the same size, the first-fit strategy works quite well. This will be the case in later examples where we'll store a single homogenous tree in a file in which the nodes are all the same size. Keep in mind that nothing stops you from storing all types of data in a single file. It's just that the first-fit allocator may not yield optimum performance for these situations. For a discussion about heap allocation strategies, see [Knuth 73].
In the allocation strategy presented here, almost no overhead is required for objects that are allocated. The free block header is used only when objects are deleted, and then the header overwrites a portion of the object. For this strategy to function properly, however, the object must be large enough to hold a free block header. The size of the header as we've defined it is eight bytes, and that's the minimum size of an allocated object. If you try to allocate a smaller object, eight bytes will be allocated anyway and some of the space will be wasted.
Recall that the header contains an integer check word. This field is used for file integrity checks. For instance, if you follow the next field of a free block header and land on a block that doesn't start with this check word, you know the file has been corrupted. The check word is optional, and if you remove it, the minimum allocated size will be reduced to six bytes. However, we strongly recommend keeping the check word because it's a great debugging aid.
A proposed addition to C++, exception handling, gives you the ability to elegantly handle errors, or exceptions, that arise during program execution. When an invalid condition is detected, an exception is thrown, and is caught by code that can hopefully make a sane recovery. For the caching design you are about to see, exception handling would be invaluable. Unfortunately, at the time of this writing, exception handling isn't yet available. So, we've implemented the following ExceptionHandler class to crudely simulate exception handling:
Complete code for the ExceptionHandler class is given on disk in the files exchdlr.h and exchdlr.cpp.
Exceptions are thrown by calling the Throw( ) function. An exception code is passed, along with parameters indicating the line number and source file where the Throw( ) function was called. Other auxiliary messages defined by the user can be passed as well. In most cases, Throw( ) prints the messages and then terminates the program. Unlike true exception handling, no attempt is made to recover from an error. The THROW( ) macro, which calls Throw( ), is provided for convenience. It sets the line number and source file parameters, and defaults the others to zero.
The exception codes are defined in the following enumeration:
The following Close( ) function of Fmgr shows how to throw exceptions. A check is made to ensure that no dangling smart pointer references will be made to the file about to be closed. An exception is also thrown if an error unexpectedly occurs when closing the file:
The Fmgr class actually has its own Throw( ) function, which traps certain exception codes and modifies them based on the context we're in:
After fixing the exception code, this function calls the basic Throw( ) function via the global exception handler pointer excp, which is declared in the exchdlr.cpp file. You can customize the exception handling by deriving a new class from ExceptionHandler and then pointing excp to a derived handler.
Here is the message that's printed when Close( ) throws a DANGLINGPTR exception:
As we've mentioned before, the excepvion handling described here is a very weak form of what is proposed for C++. For a description of the proposed design, see [Stroustrup 91].
In this section, we look at some issues involved in safely using the Fmgr class, and how handling those issues leads us logically to the caching design you are about to see.
To use a file-based object, we need two components (besides the file): a buffer for a copy of the object stored in memory and the address of the object in the file. In trivial programs (such as the fmgrtst.cpp program given earlier), working with these two components separately isn't a problem. In larger, non-trivial programs, however, four basic issues emerge:
1. When using more than one file-based object, it's easy to associate a file address with the wrong memory buffer. We need a way to keep the addresses and memory buffers paired together. We can do this by defining a structure with both components as members. We'll call such structures Buckets. Here's how a Bucket structure could be defined:
2. Nothing stops you from having two addresses that point to the same object in the file, even though each address has its own associated memory buffer. This is a particularly insidious form of aliasing. Which memory buffer has the "official" data that should be written to the file? We would like to guarantee a unique object address for each memory buffer. If we're using buckets, that means no two buckets should have identical addr members.
3. Even though each bucket should have a unique file address, we don't necessarily want to make only one reference to any given bucket. For example, assume that buckets store tree nodes and that we use pointers to buckets in implementing tree operations, such as searching and inserting. You've seen from earlier chapters that it is quite common to copy pointers during tree operations, which results in a lot of aliasing. This aliasing is bad enough for objects stored in memory, but it's even worse for file-based objects. We must ensure that bucket pointers work in concert with each other. Using smart pointers to buckets with reference counts is one way to do this.
4. In applications with a large number of file-based objects, such as a file-based tree with many tree nodes, it's not possible or desirable to keep all the objects in memory. Thus, we end up shuffling objects in and out of a fixed number of buckets and onto disk. We must keep track of which buckets can be reused at any given time--a difficult and error-prone task. It would be nice to automate this process.
We can solve all of these problems by using a collection of buckets known as a cache. The purpose of a cache is to be the intermediary mechanism between code using a file-based object and the file itself. You make requests to the cache for a particular object (keyed by its file address), and the cache sees to it that the object is fetched from disk and stored in a bucket. If the object is already in a bucket, no fetching need be done. (This, by the way, guarantees a unique file address for each bucket.) When the appropriate bucket is reserved, a pointer to the bucket is returned to be used by the code wishing to access the file-based object.
As requests are made to the cache, more buckets are reserved. Eventually, the cache fills up. When another bucket is needed, the data in one of the occupied buckets must be flushed back to disk so the bucket can be reused for the new request. A special flag can be kept with each bucket, known as the dirty bit, which indicates whether the bucket data has been modified since it was last loaded. If the dirty bit is set, the object data in the bucket is written to disk. If the dirty bit isn't set, the bucket can be reused without further action.
Of course, the problem with this scheme lies in determining which buckets can be reused. By adding reference counts to the buckets, this becomes easy: A bucket can be reused if there are no references to it. Since the buckets are reference counted, it makes sense to access them with smart pointers. The Coptrs to be presented later allow you to do just that. A Coptr is a smart pointer to a cache bucket. When Coptrs are assigned to each other, the reference counts of the corresponding buckets are updated. The reference count of the original bucket of the target Coptr gets decremented, whereas the reference count of the source bucket gets incremented. In this way, Coptrs can share buckets without any confusion.
In using a cache to solve aliasing problems, a fortuitous side effect occurs. Code that uses caching generally runs faster than code without caching. Thus, we get both safer and faster code.
Figure 13.6 illustrates the organization of a caching system that incorporates all of the design features just discussed. Next, we'll look at the design of this system in detail.
In this section, we examine the design of cache buckets. As we've done throughout the book, we'll separate the design into two parts. We'll first define buckets independently of the data stored in those buckets, then add the data. This provides the greatest amount of code sharing. Here is the Bucketb class, which defines buckets independently of the bucket data:
The addr, refcnt, and dirty members implement the features of buckets described in the previous section. Two other members, prev and next, are pointers used in organizing the buckets in a doubly-linked list. We'll discuss these pointers when the Cacheb class is examined.
The most striking feature about the Bucketb class is that it can be completely inlined. This means that very little, if any, overhead is induced by using the Bucketb class over more low-level and hard-coded techniques. Only two of the member functions, Fetch( ) and Store( ), depend on the type of data stored, so we've declared these functions as pure virtual. Three of the functions--Lock( ), Unlock( ), and IsLocked( )--are used to access and manipulate the reference count stored in the bucket. The rationale behind the names of these functions will become apparent when we dis cuss the Cacheb class.
From the Bucketb class, we can derive a template class called Bucket that defines a family of classes, each specific to a particular type of data we wish to store. There are several ways to derive the Bucket class. The first way is the most obvious; include a TYPE object inside the Bucket, as in:
To access the bucket data, we need to go through the info field. For example, suppose we define file-based tree nodes holding integers, and we wish to store these tree nodes in buckets. Here's how we might write code to use these buckets:
Going through the info field is clumsy. We would prefer to write expressions like root->left. To do this, the buckets must somehow act like tree nodes, yet we still want them to behave like buckets, too. Multiple inheritance is the perfect tool to accomplish this. Here's a new definition for Bucket that uses both Bucketb and TYPE as base classes:
Note Some compilers don't allow you to use a template parameter as a base class (even though that's perfectly legal in C++). If this is the case with your compiler, you'll have to remove the template syntax, and code this class directly for the types you have in mind. Fortunately, this class is small enough that it can be replicated by hand easily. But you'll also have to hand-code the upcoming Cache and Coptr classes.
By using multiple inheritance for the Bucket class, we can write code like the following:
The Bucket class is one of those rare classes that is simultaneously simple, elegant, and powerful. Just three functions need to be added to the Bucketb class to derive a data-dependent class: a constructor and the virtual functions Fetch( ) and Store( ).
The Fetch( ) and Store( ) routines employ a subtle but powerful trick. When it's time to fetch or store the data in the bucket, we only want to use the TYPE portion of the bucket. Members like addr, refcnt, and dirty shouldn't be stored on disk. But how do we accesss only the TYPE portion of the bucket? We can employ a little-known feature of multiple inheritance: Given a pointer D to a multiply derived object with base classes A and B, you can get a pointer to the A portion of the object by type casting D to an A pointer. Similarly, to get the B portion of D, a B pointer type cast can be used. For example:
When the compiler sees the last two statements, it calculates the pointers Aptr and Bptr by adding the appropriate offset to the this pointer of the object pointed to by Dptr. Figure 13.7 illustrates this process. Note that the precise layout of multiply-derived objects is implementation dependent. Figure 13.7 shows one possible layout. Also, the offsets to add to the this pointer are constant and can be calculated at compile time. Thus, multiply derived-to-base-class pointer conversions can be quite fast.
For a Bucket<TYPE> pointer, a TYPE pointer type cast will give you a pointer to the TYPE portion of the bucket. Thus, the Fetch( ) and Store( ) routines type cast the this pointer of the Bucket to calculate a pointer to the TYPE data. This pointer is then passed when calling the Fetch( ) and Store( ) routines of Fmgr.
In using the TYPE parameter, you need to observe these restrictions:
Complete code for the Bucketb and Bucket classes is given on disk in the files bucketb.h, bucket.h, and bucket.mth.
The main task of a cache is to handle requests for file-based objects. The cache must determine whether an object is already loaded and, if not, the cache must reserve a bucket for the object and load it in memory. However, what should the cache do when all the buckets are filled? We must provide a way for the cache to choose which bucket to overwrite with the new object. Caches are differentiated by the strategies they use to determine which buckets to reuse. For optimal performance, those buckets with data not likely to be used again soon should be chosen as candidates. In general, this is difficult to determine.
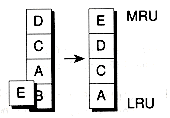
Fortunately, there is a strategy that works reasonably well. This strategy is based on the observation that, in most programs, the object most recently requested is likely to be requested again very soon. This principle is often called locality of reference. The objects currently in use tend to be localized to a small working set. As program execution proceeds, this working set slowly changes. You can take advantage of locality of reference by designing your caches to overwrite the least-recently used bucket, since that bucket is the least likely to be needed again any time soon.
Caches that overwrite least-recently used buckets are often called LRU caches. In an LRU cache, the buckets are kept in order based on how "old" the buckets are--that is, how long ago they were last used. There are various ways to "age" buckets. The simplest way is to keep the buckets on a self-organizing linked list. Each time a bucket is used, it is moved to the front of the list. Thus, the most recently used buckets tend to be at the front. Those buckets that haven't been used recently will fall to the back of the list. When a new bucket is needed, it can be chosen from the back of the list. Figure 13.8 illustrates the LRU strategy.
Our cache design uses a slight modification of the LRU strategy. We will use Coptrs that reference cache buckets directly, with each Coptr being initialized after a bucket is reserved. If we were to use a strict LRU strategy, the buckets would have to be reorganized every time a Coptr was used. This would be clearly inefficient. Instead, we reorganize the buckets only at the time a bucket is reserved. In effect, we use a least-recently reserved (LRR) strategy. Although it's difficult to prove this, the LRR strategy is likely to perform as well as, or better than, the LRU strategy.
We use two classes to implement caches. The Cacheb class incorporates those functions that are independent of the type of buckets, whereas Cache is the type-specific template version:
Complete code for the Cacheb and Cache classes is given on disk in the files cacheb.h, cacheb.cpp, and cache.h.
The type-specific Cache class adds just two functions, which handle the allocation and de-allocation of the cache buckets. The buckets are stored in an array of size n, as shown in the following Cache constructor and destructor:
Most of the code resides in the Cacheb class, which is shared among all caches. This means you can have many different caches with little source code explosion.
Although the buckets are stored in an array, the Cacheb class organizes them as a circular doubly-linked list, as shown in the following Cacheb( ) constructor. Thus, the buckets are actually organized as a hybrid structure. Unlike the circular lists we defined in Chapter 8, we don't use a dummy header node in the bucket list.
The buckets are organized in a doubly-linked list to facilitate the LRR strategy of the cache. When a bucket is reserved, it is moved to the front of the list, using the following MoveToFront( ) function. This in effect makes the bucket the most-recently reserved (MRR) bucket:
Often, MoveToFront( ) will need to move the LRR bucket at the back of the list to the front--to make it the MRR bucket. Thus, MoveToFront( ) traps for this case and uses an optimized movement. Because of the circularity of the list, only the head pointer needs to be updated.
When an object is requested from the cache, the ReserveBkt( ) function is called:
The ReserveBkt( ) function uses the file address of the object requested as a key and searches through the cache for the object by calling FindBkt( ). This latter function does a sequential search starting from the MRR bucket because, most likely, the object being requested was requested just recently.
If the requested object is not found, a bucket is acquired by calling the AcquireBkt( ) function:
Because buckets are going to be used directly via Coptrs, we can't simply have AcquireBkt( ) return the LRR bucket. That bucket may be referenced by one or more Coptrs. A bucket that has a non-zero reference count is called a locked bucket. So AcquireBkt( ) starts with the LRR bucket and searches toward the MRR bucket, stopping at the first unlocked bucket it finds. When an unlocked bucket is found, we prepare for it to be overwritten by flushing any dirty data it might contain. The bucket is then moved to the front of the list to become the MRR bucket.
It's possible that all buckets in the cache will be locked. When this occurs, the cache is full, and an exception is thrown. Note that we can't simply grab a bucket and use it. That would leave us with one or more dangling Coptrs.
After acquiring a bucket, the ReserveBkt( ) function fetches the object data from the file so that the data is loaded and ready to go. However, if the object being requested has yet to be constructed, there's no data in the file to load. The ensure_loaded flag is used to indicate this situation so that the bucket data isn't erroneously loaded.
Once a bucket has been either found or acquired, the reference count of the bucket is incremented by calling Lock( ). The bucket is then moved to become the MRR bucket. A pointer to the bucket is returned, presumably to be assigned to a Coptr.
You may want to have more than one cache connected to the same file. Recall that the Fmgr class is reference counted to handle this situation. The following Connect( ) and Disconnect( ) functions are used to connect or disconnect a cache from a file:
Recall that Fmgr Ptris a smart pointer. The assignment âptr = âin Connect( ) decrements the reference count of the old Fmgr in use and increments the reference count for â. A cache can be disconnected from a file by connecting it to the null Fmgr object, using the statement âptr = 0. Both Connect( ) and Disconnect( ) clear the cache before changing the connection. The following Clear( ) and Flush( ) functions are used:
When Clear( ) callsFlush( ), it sets the empty_bkts flag to true. This causes not only the bucket data to be flushed, but also makes the buckets "null" by setting their addr, refcnt, and dirty variables to zero. A bucket to be emptied should not have any pointers referencing it. That condition is checked and an exception is thrown if true. Thus, before calling Clear( ), all Coptrs must be unbound from the buckets they are referencing.
Since the cache buckets are reference counted, we need smart pointers to work in conjunction with them. We use cached-object pointers (Coptrs) for that purpose. Coptrs are implemented with two classes: a data independent Coptrb class and the type-specific Coptr class template:
Complete code for the Coptrb and Coptr classes is given on disk in the files coptrb.h, coptrb.cpp, and coptr.h.
Each Coptr stores the file address addr of the object being pointed to, a pointer bkt to the bucket containing the memory buffer of the object, and a pointer cache to the Cache the Coptr is connected to. Another important variable is the bound flag. This flag indicates whether the Coptr is currently bound to a bucket.
Before a Coptr can be used, it must be connected to a cache. The Coptr( ) constructor, which calls the following base class Coptrb( ) constructor, is used for this purpose:
Coptrs can optionally be given the address p of the object being referenced. Note that p defaults to zero. A Coptr with an address of zero is treated as a null pointer. Thus, by default, Coptrs are initialized as null pointers.
The main function of a Coptr is to take a file address and make it appear to be a pointer to a TYPE object. This magic is accomplished by the clever combination of smart-pointer-style reference counting and multiply-derived buckets. The two most important functions of a Coptr are the following - > and * operator functions:
Auto-Loading of Cached Objects
Detecting Modifications to Cached Objects
Allocating Objects Referenced by Coptrs
An important Coptr feature is the automatic loading of object data into the cache. Whenever a Coptr is accessed through the overloaded operators - > and *, the bound flag is checked to see whether the Coptr is currently bound to a bucket. If not, the Bind( ) function (described later) is called to reserve a bucket for the Coptr. In the operator*( ) function, a reference to this bucket is returned. The operator->( ) function returns a pointer to the bucket. (The type casts are needed because bkt is typed as a generic Bucketb pointer.)
Due to multiple inheritance, we can use the return values of our operator functions to access both the members of Bucketb and the members of TYPE. The following example constructs a Coptr to a tree node (which we defined earlier) and uses the Coptr to access the SetDirty( ) member of Bucketb and the left member of Node:
Coptrs are designed to follow one principle: A bucket isn't loaded until needed. When Coptr p is initialized to point to a Node at the file address 42 (presumably the Node has already been allocated), that Node isn't loaded into a bucket until the left member of Node is accessed.
Even though Coptrs cause file-based objects to be fetched automatically, we must tell a Coptr specifically when the objects need to be written back to disk. After the statement p->left = 17 is executed, the in-memory copy of the Node is different from what's stored on disk. We inform the cache of this fact by calling SetDirty( ). If the corresponding bucket is to be overwritten later (or the cache cleared), the cache knows to flush the bucket data to disk.
If the delay in writing the bucket data to disk is unacceptable, you can call Store( ) instead of SetDirty( ). This causes the bucket data to be written immediately. In fact, you could add a flag to the Bucketb class, which, when true, causes SetDirty( ) to store the object data to disk, rather than simply set the dirty bit. By doing this, you have in effect created what is known as a write-through cache. A write-through cache is safer than a regular cache. There's less danger of losing data that should be on disk but is still in memory when a hardware failure (such as power loss) occurs. We chose not to implement our caches this way. It's better to choose by hand whether to call SetDirty( ) or Store( ). That way, you have more flexibility in trading speed over safety.
You may wonder why we even need SetDirty( ). Couldn't the caching system automatically detect when the bucket data has been modified? The answer is yes in principle, but no in practice. You can detect when an object is modified by overloading its assignment operator, and setting the bucket's dirty bit when an assignment is detected. There are two problems, however.
First, you have to overload the assignment operator for each member of the object, and this must be done recursively if the members themselves are nested objects. The second problem is worse. Even if each member can detect assignments, how do those members set the bucket's dirty bit? Remember, nested objects don't have access to the objects that enclose them. A pointer to the dirty bit could be stored in each member, but this would waste a lot of space, and that space would be taken up in the file as well. Also, just adding the dirty bit pointers to each member would be difficult. How would you go about using predefined objects?
There are alternatives, but they are all less than satisfactory. One alternative is to keep two copies of each object in memory. The first copy represents the state of the object as it was loaded from disk. The second copy is used during all in-memory accesses. When it's time to flush the bucket, these two copies are compared to see if the second copy, containing any changes, should be written to disk. This technique would be simple to implement, but it wastes time in making the extra copies, and it also wastes storage.
You might wonder why you couldn't just set the dirty bit each time the overloaded - > and * operators are called for a Coptr. The problem is that the dirty bit would be set even if we're just reading the values of the members, rather than modifying them. The result is that the bucket data might be written back to disk during a flushing operation when it didn't need to be. You might as well forget about the dirty bits and always write cached objects back to disk, since that would have the same effect.
Coptrs are bound to buckets by calling the following Bind( ) function. This binding is usually done for you automatically, but you can do the binding yourself by calling Grab( ):
The Bind( ) function has both safety and speed considerations built in. Bind( ) assumes you are trying to bind a non-null pointer (with addr being non-zero). If that's not the case, a NULLPTR exception is thrown. This is how Coptrs check for null pointers. Note that this test only occurs when binding to a bucket, and not on every access to a Coptr. This dramatically speeds up the use of Coptrs, yet it doesn't sacrifice safety. You can pass around null Coptrs all you want, and no error occurs until you try to access the associated non-existent objects.
Bind( ) is also built for speed in another way. If the bkt pointer isn't null, a test is made to see if bkt is already pointing to the right bucket. If it is, the bucket is simply locked. This saves the searching that would otherwise be required. If bkt is null or doesn't point to the right bucket, a relatively expensive call to ReserveBkt( ) is made, which searches the cache looking for a bucket. Note that ReserveBkt( ) handles the locking of the bucket in this case. For certain applications, fast binding can take place more often than you might think. You'll see this later when we discuss recursive traversals of trees on disk.
Coptrs can be assigned by using the overloaded assignment operator, which in turn calls the Copy( ) function:
The Copy( ) function releases any bucket the destination Coptr might be referencing by calling Release( ) (described later), and then assigns the members of the source Coptr. The Coptr( ) copy constructor is similar to Copy( ) except the call to Release( ) isn't needed.
As is true with ordinary pointers, when Coptrs are copied, the data being referenced isn't copied. In fact, for Coptrs, the destination is left unbound, even though the source Coptr might be bound. This practice is in keeping with the principle that Coptrs aren't bound until needed. Using this principle has important performance ramifications. Consider operations on file-based trees. During the tree operations, many pointers are assigned, often with very transitory values. By deferring the pointer binding until it's absolutely necessary, we can ensure data isn't loaded during otherwise transitory pointer assignments.
Even though the destination is unbound, it has the source Coptr's bkt pointer. When it's time to bind the destination, it can probably be done quickly by using fast binding. The only time this wouldn't occur is if, in the interim, the referenced bucket became unlocked and overwritten.
Coptrs can also be used as though they are long file addresses. The following two operator functions help facilitate this:
These two functions allow us to work easily with file-based tree nodes, which have long integers instead of pointers for links to child nodes. For example, we can write functions such as the following GetMin( ) function:
We'll now work through this small example to see what actually occurs behind the scenes. First, the parameter t is passed by value, which causes the Coptr( ) copy constructor to be called. After the copying, t has an address, a cache pointer, and even a bucket pointer (which may point to the right bucket if we're lucky). However, t is unbound at this time.
When the while loop is entered, t is tested for null. This is accomplished by converting t to a long integer whose value is the address of the object that t points to. If that value is non-zero, we know we're pointing to a real object. Then, t is assigned to the address of its left child. The assignment operator taking a long integer is called here, since t->left is a long integer. Note that the expression t->left causes t to be bound (with the Node loaded from disk if necessary) so that the value of left is defined. However, t is immediately unbound by the assignment statement, since it takes on a new address. Upon return from the function, we make and return an unbound copy of the final version of t.
The striking observation here is that GetMin( ) looks almost identical to the function we would write if the tree resided in memory. To make a memory-based version of GetMin( ), all we need to change is how the pointers are typed.
The ability to write code for file-based objects so that it appears almost identical to code written for memory-based objects has important ramifications. If you've ever tried to write code for file-based trees, you know what we mean. For example, try writing code for red-black trees using low-level functions such as Fetch( ) and Store( ). It's a virtual nightmare due to the aliasing that occurs when pointers are being frequently assigned and modified. It's difficult to tell when something needs to be written to disk and which memory buffer has the right values. It's easy to be wrong.
By using Coptrs, it's relatively painless to write code for file-based trees. As a very fortunate side effect, the use of caching makes the code run much faster as well. In fact, using a cache for a file-based tree can make a huge difference in performance. You'll get at least double the performance, and sometimes much better than that.
Unfortunately, using Coptrs isn't always quite as transparent as we would like. In the next section, you'll see that, in some cases, we must coax the Coptrs along by manually intervening with the binding process. Also, don't forget that we must manually set dirty bits for any objects we modify. Failure to do this can wreak havoc on the data structures being stored to disk.
Coptrs are unbound from the buckets they reference by using a call to the Release( ) function:
Unlike binding, releasing Coptrs is only done semi-automatically. It's not possible to tell, in general, when a Coptr needs to be released. There are some obvious situations when we can tell, however. For instance, you saw automatic releasing during Coptr assignments. Another situation occurs when the Coptr gets destroyed. Here is the Coptr destructor:
When we use Coptrs in code involving straight iteration, the two automatic release points of assignment and destruction work just fine. However, consider the following recursive inorder traversal of a file-based tree:
Consider what happens during this function. The copy constructor for t is called during the pass-by-value parameter passing. At this point, t is unbound. In the recursive call, a temporary Coptr is created by using the copy constructor with a second argument, which indicates the address for the Coptr. The address given is to t's left child, and the expression t->left causes t to become bound. The temporary Coptr is unbound. As a side effect of the copy, the temporary Coptr gets t's cache pointer, which is important because all Coptrs are required to reference a cache. We must use the same cache that t has, or things would quickly go haywire.
When the recursive function call is made, another unbound copy of the temporary Coptr is made. This copy becomes bound during the next recursive call, and so on. When we return from a recursive call, the temporary copy gets released and destroyed automatically.
At each level of recursion, a new version of t is bound. Recall that the buckets for these bound Coptrs are locked and can't be reused. Essentially, the cache must have as many buckets as the depth of the tree, plus a few extra buckets for other Coptrs that might be in use. Otherwise, the cache would overflow. If you don't want to calculate ahead of time how big the cache needs to be (which would tend be difficult anyway), the alternative is to ensure that t is unbound during the recursion. This can be done by manually releasing t before the recursive call. We may also want to release the temporary Coptr before calling Visit( ). For example:
Note that t probably gets rebound during the Visit( ) function. If we're lucky, the rebinding will be fast, since t's bucket pointer may still be pointing to the right bucket. Remember that releasing a Coptr doesn't cause the bucket to go away. The bucket is merely made available for reuse, and then only if there are no other Coptrs referencing the bucket. If you're lucky, the bucket will still be intact when you need it again.
The conclusion from this discussion is that, as long as you're using iteration, Coptrs can be manipulated virtually the same as ordinary pointers. (You still must set dirty bits, though.) However, with recursion, the fact that Coptrs are really more than ordinary pointers becomes apparent, and we must carefully consider the bind and release points.
Since Coptrs look a lot like ordinary pointers, it would be nice if we could allocate and construct file-based objects with them using the new operator. In fact, we can, as you'll now see. The workhorse function is the following Alloc( ) function:
This function allocates n bytes (presumably sizeof(TYPE))at address p in the cache's file, and sets up a cache bucket to support it. If p isn't zero coming in, it means the TYPE object has already been allocated. (This can be used when creating a new object in the static area of the file.) Note that ReserveBkt( ) sets up the file address, cache pointer, and reference count, but it doesn't load any data. A pointer to the bucket is returned.
The Alloc( ) function is used by the following overloaded new operator:
This function has only one statement, but there's a lot of subtlety and power packed into that statement. First, Alloc( ) is called using size n and address p (which defaults to zero), and a pointer to a reserved bucket is returned. Since the pointer is typed as a generic Bucketb pointer, it is type cast to a more specific Bucket<TYPE> pointer. Then, some magic happens. We type cast the pointer to be a TYPE pointer. Recall that Bucket<TYPE> is multiply derived. Thus, the type cast to a TYPE pointer causes a pointer to the TYPE portion of the bucket to be computed. This TYPE pointer is then returned from new, and is passed to the constructor as the this pointer of the TYPE object to be constructed. (We had to pass the pointer back as a void pointer to satisfy the syntax for the new operator.)
Here is an example of the overloaded new operator in action:
The single call to new causes a Node to be allocated in the file used by the cache, a bucket to be reserved in the cache, and the Node portion of that bucket to be constructed. Note that, in effect, we're partially constructing a multiply-derived object (think about that for a while). This is a nice trick to have in your arsenal.
If you want to construct an object at a pre-allocated address (perhaps in the static area of the file), you can pass an extra parameter to new:
This form of new is the file-based analogue to in-place construction.
You can also free a file-based object by way of a Coptr. The following Delete( ) function is used. It calls a lower-level Delete( ) function of the Coptrb class.
Note that you can only call Delete( ) for Coptrs that have unique buckets or aren't bound. Otherwise, you have dangling pointers and an exception is thrown. Here is an example that uses Delete( ):
You might wonder why we can't use the delete operator. Here's one attempt at defining an overloaded version of delete:
Due to the rules of C++, we must pass a void pointer to delete. While it's easy to do a type cast to a Coptrb pointer in calling the low-level Delete( ) function, the call to delete becomes awkward since we must take the address of the Coptr during the call. For instance:
This was deemed to be too confusing and error prone, so we decided to use a Delete( ) function call instead.
On disk, you'll find complete code for building file-based binary search trees. This code uses all the techniques we've described in this chapter, and is a direct "port" of the memory-based binary search tree code given in Chapter 10. When you examine the file-based code, notice how similar the code is to the memory- based version.
Complete code for file-based binary search trees is given on disk in ftree.cpp and ftree2.cpp. The latter illustrates how easy it is to have more than one tree stored in the same file, each tree having its own cache.
You may wonder just how fast Coptrs are. Since they use caching implicitly, they will be reasonably fast. However, even disregarding slow file access, Coptrs won't be as fast as memory-based objects. That's because on every access to a Coptr, a test is made to see if it's bound. This test, while simple, still takes time. You can fine-tune the performance of your file-based objects by carefully analyzing the bind and release points, and handling the binding and unbinding yourself.
For example, you can use a Coptr initially to get access to a bucket, and then use an ordinary pointer to the bucket from that point on. Here's some code that illustrates this:
Of course, using code like this leads to a lot of unsafe aliasing, so you must be extremely careful.
You can also optimize performance by manually intervening in the LRR caching strategy. Recall that, when using the caches designed here, a bucket moves to the front to become the MRR bucket only when that bucket has just been reserved for a Coptr. During the course of using the Coptr, the bucket may actually fall to the back of the list if it hasn't been reserved by other Coptrs in the interim. You can notify the cache that the bucket is being used frequently by calling the NotifyUseOf( ) function:
For example:
You don't have to use NotifyUseOf( ). Even if a bucket is at the back of the list, it won't be reused as long as there are references to it.
In this chapter, you've seen a versatile and powerful way to manage objects stored on files. While the code is template-based to make it type-safe, there's a minimal amount of source code explosion. The classes were carefully designed so that most of the work is done with data-independent code that is shared by all types of objects stored.
To make using Coptrs simple and elegant, we've employed several multiple inheritance and type-casting tracks. Unfortunately, some current compilers can't handle the statements that use these tricks, even though legal C++ is used. However, the code as given compiles and runs fine with Borland C++ 3.1, currently the only widely used native-code compiler that supports templates.
A FILE-BASED ALLOCATOR CLASS
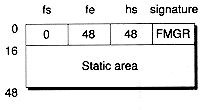
struct FmgrHeader { // Goes at the beginning of every fmgr filelong fs; // Address to first block of "heap" free space
long fe; // Address of byte after end of file
long hs; // Address of the start of the "heap"
char sg[4]; // Signature used for every fmgr-based file
};
struct FBlkHeader { // For free blocksint check_word; // For file integrity checks (optional)
unsigned len; // Length of block not including header
long next; // Pointer to next free block
};
const long CURRADDR = -1; // Indicates current location
class Fmgr : public CountedObj {public:
enum Io_op { fetch, store, seek };enum AccessMode { read_write, read_only };enum CheckWord { BLKINUSE = OxFDFD, FREEBLK = OxFEFE };protected:
char name[128]; // Name of the file
static char sg[4]; // Signature for fmgr style files
FmgrHeader h; // File header as stored in memory
FILE *fp; // Stream file handle
Io_op lastop; // Last I/O operation
cjar status; // Status bits
// Various internal functions. . .
public:
Fmgr();
virtual ~Fmgr();
virtual int Create(char *fname, long static_sz = 0);
virtual int Open(char *fname, AccessMode mode = read_write);
virtual void Close(int flush=1);
virtual void Flush();
long Alloc(unsigned nbytes);
void Free(unsigned nbytes, long p);
void Fetch(void *d, unsigned n, long p = CURRADDR);
void Store(const void *d, unsigned n, long p = CURRADDR);
void Seek(long ofs, int seek_mode = SEEK_SET);
int IsOpen() const;
int ReadOnly() const;
int ReadyForWriting() const;
void ClearErr():
void Throw(StatusCode c, char *src=0, int lno=0, char *msg=0):
int OK() const;
int operator!() const;
operator const int () const;
} ;
typedef SmartPtr<Fmgr> FmgrPtr;

Features of the Fmgr Class
// fmgrtst.cpp: Sample program using an Fmgr object
#include <iostream.h>
#include "fmgr.h"
struct Part {int id;
float price;
Part(int i=0, float p=0) { id = i; price = p; }} ;
main()
{Part part(17, 42.0); // Memory buffer of part to be stored
FmgrPtr f(new Fmgr); // Should always create dynamically
f - >Create("test.dat"); // Create and open filelong addr = f - >Alloc(sizeof(Part)); // Allocate room for part
f - >Store(&part, sizeof(Part), addr);
// Close and reopen file (for testing)
f - >Open("test.dat"); // Open() closes first// See if we can get the part back
f - >Fetch(&part, sizeof(Part), addr);
cout << "Part: <" << part.id << ", " << part.price << ">\n";
// Now delete the part
f - >Free(sizeof(Part), addr);
return 0; // (File automatically closed by destructor)
}
Layout of an Fmgr File
Figure 13.1 Fmgr file layout.
The Fmgr Heap
Figure 13.2 Fmgr header layout.
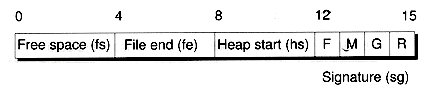
Figure 13.3 Allocating a new object.
(a)Empty heap

(b) After adding new object
Figure 13.4 Free block header layout.
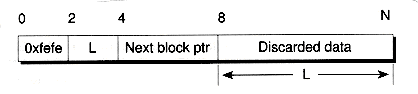
Figure 13.5 Objects on the free list.

Exception Handling
class ExceptionHandler {protected:
virtual void Report(char *src, int lno, char *msg, char *dev);
virtual void TakeAction();
public:
ExceptionCode status;
ExceptionHandler();
void Clear();
virtual void Throw(ExceptionCode c,
char *src=0, int lno=0, char *msg=0, char *dev=0);
};
#define THROW(c) Throw(c, _ FILE_, _ LINE_ )

enum ExceptionCode {DANGLINGPTR,
NULLPTR,
CACHEFULL,
STKFULL,
CLOSERR,
// Many other codes . . .
} ;
void Fmgr::Close(int flush)
// Closes the file if not already closed, flushing the
// basic header if flush = 1. Does nothing if in the
// error state. Checks for dangling references to
// this file.
{if (OK()) {if (refcnt > 1) THROW(DANGLINGPTR);
if (flush && !ReadOnly()) WriteHdr();
if (::fclose(fp) != 0) THROW(CLOSERR);
strcpy(name, closed_file_name);
}
status &= Oxfd; // Reset open bit
}
void Fmgr::Throw(ExceptionCode c, char *src, int lno, char *msg)
{if (c == NOTWRITEABLE && OK( )) c = READONLYERR;
f (c == NOTREADY && (status & 1)) c = NOTOPENERR;
excp - >Throw(c, src, lno, msg, name);
status &= Oxfe; // Reset good bit
}
EXCEPTION on line 132 of fmgr.cpp
Dangling 'smart pointer'
Error occured with file tree.dat
TOWARD A CACHING SYSTEM
template<class TYPE> struct Bucket { TYPE data; long addr; } CACHE BUCKETS
class Bucketb {protected:
long addr; // Location of bucket's data in the file
int refcnt; // How many references to this bucket
char dirty; // True when data doesn't match what's in file
Bucketb *prev; // Pointers to adjacent buckets in the cache
Bucketb *next; // in most-recently reserved order.
void MakeNull() { addr = 0; refcnt = 0; dirty = 0; }public:
Bucketb() {} // Other classes do the initializationvoid Lock() { ++refcnt; }void Unlock () { -refcnt; }int IsLocked() { return refcnt; }void SetDirty() { dirty = 1; }int IsNull() { return addr == 0; }void Flush(Fmgr &f) { if (addr && dirty) Store(f); }virtual void Fetch(Fmgr &f) = 0; // Depends on bucket data
virtual void Store(Fmgr &f) = 0; // Depends on bucket data
friend class Cacheb;
friend class Coptrb;
friend void Report(Cacheb &c, int full_report=0);
};
Figure 13.6 Organization of a caching system
template<class TYPE>
class Bucket : public Bucketb {public:
TYPE info;
// Other definitions ...
} ;
struct Node {char data; // The node data
long left, right; // We use long integers, not pointers
Node( );
Node(const char &x, long left=0. long right=0);
} ;
. . .
Bucket<Node> *root;
. . .
root - >info - >left = 42L; // Set the left child of root
template<class TYPE>
class Bucket : public Bucketb, public TYPE {public:
Bucket();
virtual void Fetch(Fmgr &f);
virtual void Store(Fmgr &f);
} ;
Bucket<Node> *root;
. . .
root - >left = 42L; // Accessing one of TYPE's members
root - >SetDirty( ); // Accessing one of Bucketb's members
template<class TYPE>
Bucket<TYPE>::Bucket( )
// Calls default Bucketbt() and TYPE() constructors
{}
template<class TYPE>
void Bucket<TYPE>::Fetch(Fmgr &f)
// Fetch TYPE object data from the file f
{f.Fetch((TYPE *)this, sizeof(TYPE), addr);
dirty = 0;
}
template<class TYPE>
void Bucket<TYPE>::Store(Fmgr &f)
// Store TYPE object data onto the file f
{f.Store((TYPE *)this, sizeof(TYPE), addr);
dirty = 0;
}
class D : public A, public B { ... };D *Dptr; A *Aptr; B *Bptr;
Aptr = (A *)Dptr; // Grab A portion of D
Bptr = (B *)Dptr; // Grab B portion of D
 TYPE should not have any embedded pointers. The values of pointers are transitory, changing from one program invocation to the next. Thus, it's of little use (and probably erroneous) to store pointers on disk. However, you can store file offsets (usually in long integers). These offsets can be used to reference other file-based objects, and can take the place of pointers. The tree node example we gave earlier illustrates this. TYPE cannot have any virtual functions. If TYPE has virtual functions, the virtual function table pointer will be stored on disk with the object. Of course, the value of this pointer may not be valid from one program invocation to the next. You could arrange to have the virtual function table pointer updated to the correct value after the object has been loaded, but that is highly implementation dependent. (This approach would be dependent on the way objects are organized, which isn't standardized.) TYPE should not have a destructor. Although the compiler-generated destructor of Bucket will implicitly call the TYPE destructor, it is not clear that the TYPE destructor can do anything that makes sense. The cache classes to be presented are not set up to call the TYPE destructor when a bucket is overwritten, thus TYPE shouldn't have a destructor (other than an empty one). TYPE must have a default constructor. The Bucket class constructor requires a default TYPE constructor. It's also useful for TYPE to have other constructors, as you'll see later. TYPE cannot be a built-in type. That's because TYPE is used as a base class of Bucket, and built-in types can't be used as base classes.
TYPE should not have any embedded pointers. The values of pointers are transitory, changing from one program invocation to the next. Thus, it's of little use (and probably erroneous) to store pointers on disk. However, you can store file offsets (usually in long integers). These offsets can be used to reference other file-based objects, and can take the place of pointers. The tree node example we gave earlier illustrates this. TYPE cannot have any virtual functions. If TYPE has virtual functions, the virtual function table pointer will be stored on disk with the object. Of course, the value of this pointer may not be valid from one program invocation to the next. You could arrange to have the virtual function table pointer updated to the correct value after the object has been loaded, but that is highly implementation dependent. (This approach would be dependent on the way objects are organized, which isn't standardized.) TYPE should not have a destructor. Although the compiler-generated destructor of Bucket will implicitly call the TYPE destructor, it is not clear that the TYPE destructor can do anything that makes sense. The cache classes to be presented are not set up to call the TYPE destructor when a bucket is overwritten, thus TYPE shouldn't have a destructor (other than an empty one). TYPE must have a default constructor. The Bucket class constructor requires a default TYPE constructor. It's also useful for TYPE to have other constructors, as you'll see later. TYPE cannot be a built-in type. That's because TYPE is used as a base class of Bucket, and built-in types can't be used as base classes.Figure 13.7 Multiple inheritance and type casting


CACHING STRATEGIES
The Cache Classes
class Cacheb {protected:
long hits, misses; // For performance statistics
int nbuckets: // Size of cache
FmgrPtr fptr; // File cache is connected to
Bucketb *head; // Most recently reserved bucket
Bucketb *AcquireBkt();
Bucketb *FindBkt(long addr);
void MoveToFront(Bucketb *b);
Cacheb(Bucketb *b, int n, unsigned bkt_size);
virtual ~Cacheb();
public:
friend class Coptrb;
void Connect(FmgrPtr &fp);
void Disconnect();
void Flush(int empty_bkts = 0);
void Clear();
virtual Bucketb *ReserveBkt(long addr, int ensure_loaded = 1);
friend void Report(Cacheb &c, int full_report = 0);
};
template<class TYPE>
class Cache : public Cacheb {protected:
Bucket<TYPE> *buckets;
public:
Cache(int n);
virtual ~Cache();
};
Figure 13.8 A self-organizing LRU Cache
(a) Requesting an object already in the cache

(b) Requesting an object not in the cache, with an empty bucket
(c) Requesting an object not in the cache, with no empty buckets

template<class TYPE>
Cache<TYPE>::Cache(int n)
// Allocate buckets. Send them to Cacheb() for further setup.
: Cacheb(buckets = new Bucket<TYPE>[n], n, sizeof(Bucket<TYPE>))
{}
template<class TYPE>
Cache<TYPE::~Cache()
{if (fptr) Flush(); // Process all pending bucket writes
Disconnect(); // Disconnect from the file manager
delete[] buckets;
}
Cacheb::Cacheb(Bucketb *b, int n, unsigned bkt_size)
// Assumes n buckets of size bkt_size have already been
// allocated. Sets up their prev and next pointers to form
// a circular list.
: fptr(0) // Start with a null file manager
{Bucketb *p = b;
for (int i = 0; i<n; i++) {p->MakeNull();
p->prev = (Bucketb *)((char *)p - bkt_size);
p->next = (Bucketb *)((char *)p + bkt_size);
p = p->next;
}
// Make the list circular
Bucketb *tail = (Bucketb *)((char *)b + (n-1)*bkt_size);
tail->next = b;
b->prev = tail;
// Set up other cache variables
nbuckets = n; head = b; hits = 0; misses = 0;
}
void Cacheb::MoveToFront(Bucketb *b)
// Logically move bucket to front of list so that it is
// treated as the most recently reserved bucket.
// Shortcuts are used when possible.
{if (b == head - >prev) { // b is tailhead = head - >prev;
}
else if (b != head) {// Unhook bucket from where it is
b - >prev->next = b - >next;
b - >next->prev = b - >prev;
// Put it before head
b - >next = head;
b - >prev = head - >prev;
b - >prev - >next = b;
head - >prev = b;
head = b;
}
}
Bucketb *Cacheb::ReserveBkt(long addr, int ensure_loaded)
{Bucketb *b;
if (addr == 0) return 0; // Don't reserve bkt for null object
b = FindBkt(addr);
if (b == 0) { // Bkt data not loaded, so acquire a bucketmisses++;
b = AcquireBkt();
if (b) {b->addr = addr;
if (ensure_loaded && addr) b->Fetch(*fptr);
if (!fptr->OK()) b = 0; else b->Lock();
}
}
else {hits++;
MoveToFront(b);
b->Lock();
}
return b;
}
Bucketb *Cacheb::FindBkt(long addr)
{Bucketb *b = head; // Start with the MRR bucket
do {if (b - >addr == addr) return b;
b = b - >next;
} while(b != head);
return 0; // No bucket found
}
Bucketb *Cacheb::AcquireBkt()
{Bucketb *b = head->prev; // LRR bucket
while(1) {if (!b->IsLocked()) break;
b = b- >prev;
if (b == head->prev) {excp->THROW(CACHEFULL); // Most likely will exit program
return 0; // Make compiler happy
}
}
b->Flush(*fptr);
MoveToFront(b);
return b;
}
void Cacheb::Connect(FmgrPtr &f)
// Connects cache to file f, assumed already opened
{Clear( ); // Flush any pending data for the old file
fptr = f; // Connect to a new one
}
void Cacheb::Disconnect()
// Disconnects cache from the file it was connected to
{Clear(); // Flush any pending data
fptr = 0; // Connect to null object
}
void Cacheb::Clear()
// Flush all buckets in the cache, and then null them out
{if (fptr) Flush(1);
hits = 0; misses = 0;
}
void Cacheb::Flush(int empty_bkts)
// Flushes all buckets in the cache. Makes them empty if
// empty_bkts is true. Checks for dangling Coptrs.
{// Flush, starting at the front
Bucketb *b = head;
do {if (empty_bkts && b->IsLocked()) excp->THROW(DANGLINGPTR);
if (fptr->ReadyForWriting()) b->Flush(*fptr);
if (empty_bkts) b->MakeNull();
b = b->next;
} while(b != head);
}
CACHED-OBJECT POINTERS (COPTRS)
class Coptrb { // Data independent base class for Coptrsprotected:
long addr; // File address of bucket data
Bucketb *bkt; // Pointer to bucket in the cache
Cacheb *cache; // Pointer to the cache being used
char bound; // True if pointer is bound to a bucket
void Copy(const Coptrb &c);
Bucketb *Alloc(unsigned n, long p=0);
void Delete(unsigned n);
void Bind();
Coptrb(Cacheb &c, long p);
Coptrb(const Coptrb &c);
void operator=(const Coptrb &c) {} // Disallowedpublic:
~Coptrb();
void Grab();
void Release();
void NotifyUseOf();
operator long() const;
};
template<class TYPE>
class Coptr : public Coptrb {public:
friend void *operator new(size_t n, Coptr<TYPE> &cp, long p);
void Delete();
Coptr(Cache<TYPE> &c, long p = 0);
Coptr(const Coptr<TYPE> &c);
void operator=(const Coptr<TYPE> &c);
void operator=(long p);
Bucket<TYPE> &operator*();
Bucket<TYPE> *operator - >();
} ;

Coptrb::Coptrb(Cacheb &c, long p)
// General Coptr constructor. Note that a cache
// is required. The Coptr stays unbound until needed.
{cache = &c; addr = p; bound = 0; bkt = 0;
}
template<class TYPE>
Bucket<TYPE> &Coptr<TYPE>::operator*()
{if (!bound) Bind();
return *(Bucket<TYPE> *)bkt;
}
template<class TYPE>
Bucket<TYPE> &Coptr<TYPE>::operator->()
{if (!bound) Bind();
return (Bucket<TYPE> *)bkt;
}
Auto-Loading of Cached Objects
#include "coptr.h"
main()
{FmgrPtr f(new Fmgr); // Set up a file
f->Open("test.dat"); // Open itCache<Node> c(12); // Set up a cache of 12 buckets
c.Connect(f); // Connect it to the file
// Construct a Coptr pointing to a Node at file address 42
Coptr<Node> p(c, 42L);
p->left = 17L; // 'left' member of Node accessed
p->SetDirty(); // Call Bucketb's SetDirty() function
p.Release(); // Must release Coptr before clearing cache
c.Disconnect(); // Disconnect the cache; all buckets flushed
f->Close( ); // Close the file; all buffers flushed
}
Detecting Modifications to Cached Objects
Binding Objects
void Coptrb::Bind( )
// Binds the Coptr to a bucket containing data stored at
// file location addr. Note that we may already be pointing
// to the correct bucket, so check for that.
// Assumes the Coptr not already bound. For internal use only.
{if (bkt && bkt->addr == addr) { // Fast bindingif (addr) {bkt->Lock();
bound = 1;
}
else excp->THROW(NULLPTR);
}
else {bkt = cache->ReserveBkt(addr, 1);
if (bkt) bound = 1; else excp->THROW(NULLPTR);
}
}
void Coptrb::Grab()
// Like Bind(), but makes no assumptions about the Coptr
// being unbound coming in. For public use.
{if (!bound) Bind();
}
Assigning Coptrs
template<class TYPE>
void Coptr<TYPE>::operator=(const Coptr<TYPE> &c) {copy(e); }void Coptrb::Copy(const Coptrb &c)
{Release();
addr = c.addr; bkt = c.bkt; bound = 0; cache = c.cache;
}
template<class TYPE>
Coptr<TYPE>::Coptr<TYPE>(const Coptrb &c)
{addr = c.addr; bkt = c.bkt; cache = c.cache; bound = 0;
}
Coptrb: :operator long() const
// We let a Coptr look like a file address, since in a way
// it's just a smart version of a file address
{return addr;
}
template<class TYPE>
void Coptr<TYPE>::operator=(long p)
// Redirects the Coptr to a new address. Releases the old
// bucket (if any) and does not bind to a new one.
{Release();
addr = p;
}
// File-based example
struct Node {char info;
long left, right;
Node();
Node (const char &x, long 1=0, long r=0);
}
Coptr<Node> GetMin(Coptr<Node> t)
// Get the minimum node of tree t
{while(t) t = t->left;
return t;
}
// Memory-based example
struct Node {char info;
Node *left, *right;
Node();
Node(const char &x, node * 1=0, node * r=0);
}
Node *GetMin(Node *t)
// Get the minimum node of tree t
{while(t) t = t->left;
return t;
}
Releasing Coptrs
void Coptrb::Release()
{if (bound) {bkt->Unlock();
bound = 0;
}
}
Coptrb::~Coptrb() {Release(); }void InOrder(Coptr<Node> t)
{while(t) {InOrder(Coptr<Node>(t, t->left));
Visit(t);
t = t->right; // Automatic releasing takes place here
}
}
void InOrder(Coptr<Node> t)
{while(t) {Coptr<Node> temp(t, t->left);
t.Release(); // Must do this or cache becomes full
InOrder(temp);
temp.Release( ); // May want to do this
Visit(t); // t probably gets rebound during this call
t = t->right; // t will be rebound here if not already bound
}
}
Allocating Objects Referenced by Coptrs
Bucketb *Coptrb::Alloc(size_t n, long p)
{Release( ); // Let go of any currently bound data
if (p == 0) p = cache->fptr->Alloc(n);
bkt = cache->ReserveBkt(p, 0);
if (bkt) {bkt->SetDirty(); // Data to be modified by the constructor
addr = p;
bound = 1;
}
else {addr = 0; // bound will = 0 here as well
}
return bkt;
}
template<class TYPE>
void *operator new(size_t n, Coptr<TYPE> &cp, long p)
{return (TYPE *)((Bucket<TYPE> *)(cp.Alloc(n, p)));
}
Coptr<Node> t(cache); // Set up a null Coptr
new(t) Node('a', 0, 0); // Allocate and construct a Nodenew(t, 42L) Node('a', 0, 0); // Construct object at address 42template<class TYPE>
void Coptr<TYPE>::Delete()
// Frees the data associated with the Coptr c. The Coptr is
// then set to null.
{Coptrb::Delete(sizeof(TYPE));
}
void Coptrb::Delete(unsigned n)
// De-allocates the file object pointed to by this Coptr, supposedly
// of size n. De-allocation only takes place if this Coptr is
// pointing to a bucket bound by nothing else. The Coptr is unbound
// afterward and both the bucket and the Coptr are made null.
{if (bound && bkt->IsLocked( ) == 1
!bound && (!bkt
!bkt->IsLocked())) {cache->fptr->Free(n, addr);
Release();
bkt->MakeNull();
addr = 0;
}
else excp->THROW(DANGLINGPTR);
}
Coptr<Node> t(cache); // Set up a null coptr
new(t) Node('a', 0, 0); // Allocate and construct a Node. . . .
t.Delete( ); // Free the Node from the file
template<class TYPE>
void Coptr<TYPE>::operator delete(void *p)
{((Coptrb *)p)->Delete(sizeof(TYPE));
}
Coptr<Node> t(cache); // Set up a null coptr
new(t) Node('a', 0, 0); // Allocate and construct a Node. . . .
delete &t; // Must take the address of t
CREATING FILE-BASED BINARY SEARCH TREES

PERFORMANCE TUNING
Coptr<Node> t(cache);
new(t) Node('a', 0, 0);. . .
Bucket<Node> *p = &(*t); // Get direct bucket pointer
. . .
p->left = 42; // Access bucket directly
p->SetDirty();
. . .
t.Release(); // p no longer valid
void Coptrb::NotifyUseOf()
// Moves the referenced bucket to the front of the
// cache queue. For cache performance tuning.
{if (bound) cache->MoveToFront(bkt);
}
Coptr<Node> t;
. . .
t.NotifyUseOf();
SUMMARY