


This chapter should help explain why the data structures you'll see in later chapters are designed the way they are. We advocate a direct approach to data structure design, with concrete data types and templates playing a major role.
As you implement different data structures, you'll probably begin to build your own library containing the most effective and elegant designs. There are two fundamental ways you can go about this:
 Design the tools using concrete data types
Design the tools using concrete data types
Design the tools using abstract data types
Concrete data types represent direct implementations of a concept, usually designed for specific purposes. For instance, the list and node classes used in Chapter 2 are concrete, since they give a specific implementation for linked lists and only work with character nodes. In contrast, abstract data types provide a general-purpose design; the idea is to allow the user to program at a fairly high level, with all the low-level details kept hidden. Abstract data types have concrete data types somewhere in their implementations. Typically, an abstract data type might provide two or more concrete data types as alternative implementations that can be interchanged freely, without disturbing too much of an existing application.
To see an example of a concrete data type, take a look at this very simple, and very hard-coded, character stack:
class ChStack {
private:
char data[32]; // Room for 32 characters
int top; // Index to top of stack
public:
ChStack( ) { top = 0; }
void Push(const char &c) { data[top++] = c; }
void Pop(char &c) { c = data[-top]; }
};
In many ways, classes like ChStack embody the best aspects of C++. The ChStack class is very efficient, almost and possibly as efficient as a more low-level design would be, yet encapsulation is used effectively. You can only access the contents of the stack through the conventional push and pop stack operations, and you can easily create multiple stacks without worrying about the stack variables interacting with each other. If you use this class in an application, and then later decide to use a more sophisticated implementation (perhaps one that does error checking), it would be simple to make the replacement. The code for the main part of the application might not even have to be changed.
The built-in types--such as int, float, and double--are concrete data types. It's also possible to make user-defined concrete data types that look like built-in types. This can be accomplished by judicious use of constructors, destructors, and overloaded operators. Many C++ implementations provide a complex number class along these lines. You can use the arithmetic and comparison operators on the complex numbers just as you would for any int or float. In this section, we'll take a similar approach and sketch out the implementation for rational and compound numbers.
A rational number is a representation for fractions. Each rational number has a numerator and a denominator. You can extend the notion of rational numbers to include a whole number part as well. A compound number contains both a whole number part and a fractional part (that is, a rational number). The following code highlights the main features of a Rational class and a Compound class used to implement rational and compound numbers:
Besides having the usual assortment of constructors, a destructor, and an overloaded assignment operator, the Rational and Compound classes implement most of the arithmetic operators, as well as the comparison operators. The idea is to make rational and compound numbers work just like ordinary integers or floats work for standard arithmetic and comparison operations.
The details of the Rational and Compound classes are beyond the scope of this book. See the code note below for more information. Our main goal here is to show that classes like Rational and Compound are good examples of concrete data types.
The code for the Rational class, along with a test program, can be found on disk in the files rational.h, rational. cpp, and rattst.cpp. The code for the Compound class, along with a test program, can be found in the files cmpnd.h, cmpnd.cpp, and cmpndtst.cpp.
Abstract data types are the opposite of concrete data types, but are just as useful. The idea is to avoid being committed to a specific implementation. For instance, a stack can be implemented using an array or by using a linked list. At a high level, it doesn't matter which of these structures you use. What matters is that the operations push and pop are defined.
Abstract data types can be realized in C++ by using a class derivation hierarchy. The base class of the hierarchy spells out the operations to be performed on the abstract data type, providing as few details as possible. The derived classes then provide more concrete implementations. It's often advantageous to make the base class an abstract class, which has one or more pure virtual functions. A pure virtual function is a virtual function that does not have a body. Instead, the body is set to null. For example, here is an abstract character stack class:
The functions Push( ), Pop( ), IsEmpty( ), and IsFull( ) are all pure virtual functions. Since they have no bodies, it's not possible to actually call these functions (without getting runtime errors). Instead, the idea is to derive one or more classes that override these functions. The consequence is that you can't directly declare an object of an abstract class. You must only work with derived class objects. However, you can use abstract class pointers (or references), which point to derived class objects. For example:
Code that uses abstract class pointers in this manner can be quite versatile.
Even though you can't directly declare abstract class objects, it's possible to cause their copy constructors or overloaded assignment operators to be invoked. Consider the following code:
Normally you wouldn't do this, but it may happen by accident. The way to prevent accidental assignments like this is to define an overloaded assignment operator and make it private, as we did earlier for the ChNode class. We use this technique on the AbsChStk class for both the assignment operator and the copy constructor.
Once you have an abstract class defined, you can derive concrete implemenations in two ways: using single inheritance or using multiple inheritance. With single inheritance, the derived class has only one direct parent. With multiple inheritance, the derived class may have two or more parents. Figure 3.1 illustrates these techniques within the context of creating stack classes.
Let's look first at using the single inheritance technique for deriving classes. Here's how we might derive an array-based stack from the abstract stack class:
The storage for the stack is allocated dynamically to hold up to n elements using a constructor and de-allocated using the destructor:
Again, we provide a full complement of constructors and an overloaded assignment, even though we may never need to use them. They provide us with an element of safety. Both the copy constructor and assignment operator (not shown), work by copying the stack data, rather than by copying just the pointer to the data.
The interesting part is how the pure virtual functions are overloaded in ChArrStk to implement array-based stack operations:
Both Push( ) and Pop( ) check for the stack being full and empty, respectively, before allowing the operations to occur. The IsEmpty( ) and IsFull( ) functions check the current top of the stack to see if it is in bounds, given the size of the array holding the stack data.
How efficient is the derived stack compared to the concrete stack we gave earlier? The derived stack class will be slower, due to the overhead caused by the indirect virtual function calls. In addition to this performance hit, the use of virtual functions also reduces the chances that the functions can be made inline. In our concrete stack class, Push( ) and Pop( ) could be inlined, resulting in significant performance gains. Whether this matters depends on how often Push( ) and Pop( ) are called and how tight a loop they might be in. For many applications, the virtual function overhead may not be noticeable.
Next, let's derive a list-based stack class:
This class is very similar to the ChList class we provided in Chapter 2. It even uses the same cooperating ChNode class to define the nodes of the stack. The main difference is that the list operations are defined in terms of stack operations. The Push( ) and Pop( ) routines are the same as the AddToFront( ) and RmvFront( ) ChList routines. For example, here's the Push( ) routine:
The code for the array and list-based stacks, using single inheritance, is given on disk in the files stk1.cpp and stk2.cpp, respectively. The abstract stack class is given in the file abschstk.h.
In the previous section, we derived a list-based stack class from scratch. But you might have wondered why we didn't use the existing ChList class. In fact, we can do this by using multiple inheritance. This technique is one of the main uses of multiple inheritance. The basic idea is to merge one class with another, creating a new type of class. It's like doing genetic cross breeding. For instance, we can merge AbsChStk with ChList to create a new ChListStk class:
The trick is to override the virtual functions of the abstract base class and make calls to the list class to perform the operations. For example, here's how Push( ), Pop( ), IsEmpty( ), and IsFull( ) are defined:
Notice how we had to qualify the IsEmpty( )and IsFull( ) function calls to avoid ambiguities. That's because both AbsChStk and ChList have IsEmpty( ) and IsFull( )functions. Resolving ambiguities like this is one reason why multiple inheritance can be tricky to use.
One subtle feature of our derived class is that we used private inheritance for the ChList base class. By doing so, we disallow the user of the stack class from directly calling the list-oriented functions (such as AddToFront( )). We also disallow stack objects from being used as lists. We want to use the stack in terms of stack operations, not list operations.
How well does the multiple inheritance approach perform? Due to the multiple base classes, there is more overhead in virtual function calling. As a result, the runtime performance may be slightly slower than it would be for single inheritance. The class will probably also consume more space. However, these costs may be small prices to pay for the ability to elegantly piece together new classes from existing ones.
A complete running program using a list-based, multiply-derived stack class is given on disk in the file stk4.cpp. Also, a corresponding array-based version is given in stk3.cpp, and in the files charr.h and charr.cpp.
The AbsChStk class that we created in the previous section is fairly general, but not as general as it could be. AbsChStk only works for stacks that store characters. But what if we want to store integers, or floats, or window objects? Ideally, we want the type of element that gets stored to be a parameter to the basic stack type itself. We can do this through the use of templates, which are C++'s way to implement parameterized types. Concrete data types and abstract data types can both be made into templates.
Let's return to our first concrete stack class and parameterize it so that we can define it for different types of elements. Here is the original definition:
Note how we explicitly define the stack data to be of type char. We can make this definition more general by using a typedef to define the stack data type. While we're at it, we'll use a constant to define the size of the stack, and change the class name to Stack:
Now, by changing the definition of TYPE and SIZE, we can easily define the stack to work with any type, and be any size we desire. Unfortunately, we can only define TYPE and SIZE once, which means we can't easily define more than one stack class. For example, we can't define a stack of windows as well as a stack of characters. Nor can we have a stack of 10 characters in conjunction with a stack of 100 characters.
The solution is to use C++ templates. Here is the stack class rewritten using templates:
The template<> syntax is placed in front of the class definition. Between the < > brackets are the parameters that you want for the template. You can have two kinds of parameters: those that specify type names and those that specify constant expressions. Type names are identified by using the class keyword. (This use of the class keyword has nothing to do with its other use--to define classes.) You can use any valid type name as a parameter, such as char, float, or ChNode. You can even use another parameterized type! For constant expression parameters, you must specify the type of the expression, otherwise it defaults to int.
With our stack template in hand, we can now define different types of stacks, then declare objects from them. For example:
Each of these declarations defines a new stack type and then creates an object of that type. The third declaration defines a stack of linked lists (for some exotic purpose, presumably). Syntax such as Stack<char, 32> is known as a template declaration. You can use template declarations anywhere a type name can be used. For example, a template declaration can be used in a typedef statement:
Template declarations actually cause classes to be generated internally by the compiler. Each generated class is called a template instantiation. For example, the compiler might internally generate the following class for the declaration Stack<ChList, 42>. (We've given the generated class an arbitrary but presumably unique name.)
For every template declaration with different parameters, the compiler creates a new instantiation of the template. With templates, we're reusing source code rather than compiled code. This is both the boon and the bane of templates. There is no runtime overhead associated with templates. A class instantiated from a template will be just as efficient as one defined directly. Unfortunately, a classic speed versus space tradeoff occurs, because each new template instantiation increases the program's code space. All of the methods of the class must be replicated (and then modified accordingly). Taken to the extreme, this is known as source code explosion.
With our stack template, the space requirements can become severe. Not only is a new class generated each time we use a new stack element type, but each time we declare a stack of a different size. For instance, the following declarations cause two stack classes to be generated:
If, however, both parameters were to match in the declarations, only one stack class would be generated (as long as the compiler is smart enough not to generate the class twice). This is true even if we use parameters that appear different but are really the same. For instance, the following code creates two objects but only one stack class:
One way to alleviate the code explosion in our stack template is to take the size parameter out of the template and place it in the stack constructor instead. This technique changes the allocation of the stack data from static to dynamic, as in the following code:
The constructor takes care of the allocation, and the destructor de-allocates the data. Compare the way we create objects from this new stack template with the old way:
Is it better to statically allocate or dynamically allocate the stack data? The dynamic method is certainly more flexible and leads to less source code explosion. However, it requires the use of a heap. With static allocation, we don't need a heap. This means we could more easily use a statically allocated stack in environments with scarce resources, such as ROM-based process control software.
A sample program using a stack template similar to the one just show is given on disk in the file stktpl.cpp.
You can also define function templates. Actually, we've already done this with the stack class, since the stack methods are all templates. You may not have realized this because the methods were declared inline. To show the template syntax, we'll declare a few of the stack methods outside the class:
The template< > parameter list is placed in front of function templates, as is the case with class templates. Recall that class methods are qualified with the class type, using the :: scoping operator. For class templates, the class type is parameterized. That's why we use the following syntax to qualify the functions:
Note that we don't use the syntax Stack<TYPE>::Stack<TYPE>(int sz) for the constructor. The function name Stack isn't parameterized, just as the function name Push isn't parameterized. Only the type name is parameterized.
Class methods aren't the only types of functions that can be made into templates. For example, we can parameterize a sort function, such as the following InsertionSort( ) routine. (See the companion volume for an explanation of insertion sorting [Flamig 93].)
This sorting template will work for arrays of most types of data. For instance, we could sort an array of compound numbers as follows:
When the compiler sees this function call, it looks at how the array is defined and determines that the TYPE parameter is Compound. It then generates a sort function specific to compound number arrays. Here's a sketch of what's generated:
Although the sort template will work for most array types, it does make one assumption. The operator < must be defined for TYPE. Thus, the template would work fine for integer arrays, float arrays, and so on, but you must be careful with arrays of user-defined objects. In our example, we defined < for compound numbers, so we're safe. If < isn't defined for TYPE, a compiler error will be generated.
In general, the types you use as parameters to templates should be fairly robust. At the very least, these types should have well-defined default constructors, copy constructors, and assignment operators. Also, if your function plates involve any arithmetic or comparison operations, you must ensure that the template parameter types have these operations defined as well. In fact, the closer the types are to looking like built-in types (as is the case with compound numbers), the more likely it is that you won't have problems.
A typical problem occurs when you try to sort character strings with a sort function template. For instance:
Will this work as expected? No. The problem lies in the compare statement within the sort function:
Since the items being sorted are actually character pointers, we're sorting the values of the pointers instead of the text being pointed to. Thus, we would get back the array sorted by addresses. One solution is to define a class to handle the comparisons. For example:
Another method is to override the sort function template itself and provide a specific version just for character strings. You can override a function template for a specific set of template parameters by providing a function that takes the correct parameters. For example, here is a character string insertion sort function:
Here, we've replaced TYPE with char *, and we've modified the while loop to call the strcmp( ) function. If the compiler sees this function when trying to instantiate the InsertionSort( ) template for char *, it will use the function instead of the template. We can make the compiler use the overriding function by placing its function prototype in the same header file where the template occurs. The exact placement is implementation dependent. (We'll discuss the implementation-dependent details of templates later in this chapter.)
The InsertionSort( ) template is small enough to be easily overriden for different array element types. In general, though, the first method we described (defining the > operator properly through a String class) is probably a better solution. However, overriding template functions can be quite handy, as you'll see in later chapters. Also, there are other ways to handle the comparison operator problems for sort function templates. The book [Stroustrup 91] discusses some additional techniques that you can use.
Although most functions can be turned into templates, there is a restriction: Each parameter of the template must somehow be used in the parameters of the function. Why is this necessary? The compiler can only determine which template instantiation to use for a function call by looking at the function parameter types. For example, in the InsertionSort( ) function, the array parameter's type determines the template parameter TYPE. Here are some examples of illegal function templates:
This restriction isn't as noticeable for member functions. You don't need to explicitly use the template parameters here. Why? Each member function has a hidden this pointer passed as an argument, and this argument will have all of the template parameters as part of its type specification. For instance, the stack constructor is actually represented internally as something like:
Since templates can cause source code explosion, you may wonder if they are really all that useful. If you were to use the InsertionSort( ) template for 20 different array types, then 20 different sort routines would be generated. A more general sort routine, built to use abstract class pointers and virtual functions, might be better in this case. But how often would you actually use a sort template for 20 different types, in any given application? Probably not as often as you might think. If the number of instantiations is small, and the templates in question are small, the total code space for the templates might actually be smaller than the space required for a general-purpose, inheritance-oriented version. In any case, the templates will most likely be faster.
You can sometimes get the best of both worlds by combining templates with inheritance. The idea is to create a base class that does most of the work, and then derive class templates that work for specific types. For example, consider the following RecFile class, which is designed to make it easy to do record-oriented I/O with file stream objects:
With this class, the record size is stored in recsize, which is then used by the Seek( ) and IO( ) routines to compute the actual byte offset of a record. The trouble is that to read and write records, IO( ) uses a void pointer to pass the record data. Obviously, this isn't very type-safe, so we've made IO( ) a protected member. To actually use the RecFile class, you must derive classes that are type specific. The following FileOf derived class template shows how:
Note how sizeof(TYPE) is passed to the base class RecFile( ) constructor to determine the record size, and how Read( ) and Write( ) cause the necessary type conversions to be performed when calling IO( ). Here's a sketch of how you might use FileOf:
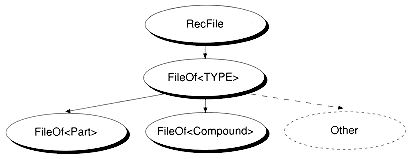
By using FileOf, we can implement an entire family of record-oriented file classes, one for each type of record, as shown in Figure 3.2. FileOf is especially useful because it is type-safe, but because it uses inline functions exclusively it may not cause any extra code to be generated. Classes such as FileOf are often called interface classes, and they show once again that C++ can be both efficient and high level.
A complete running program using the RecFile and FileOf classes can be found on disk in the files recfile.h, recfile.cpp, and rftst.cpp.
As of this writing, the implementation of templates has not been completely standardized for the C++ language. The most significant problem lies in trying to keep all the template instantiations straight. There are three main difficulties:
To solve the first two problems, the ideal solution is to have the compiler automatically determine when a template is first being instantiated for a given set of parameters, and to prevent further instantiations. Currently, there is no standard way of doing this. However, two basic approaches have emerged:
1. Include the complete template definition in a header file--methods and all. That way, wherever the template is used, the compiler has all the information about the template at its disposal. Since header files are often included in more than one source file, this can lead to multiple definition errors. Some compilers have smart linkers that detect these cases and throw out all but one of the instantiations.
2. Include only the class template definitions (but not the non-inline functions) in the header files. For non-inline function templates, include only the function prototypes. In one or more special source files, define the methods (and function bodies) for the templates, and then instantiate them for all sets of template parameters to be used by the application. Then link these source files into the application.
In this book, we will use the first approach (including all the template definitions in the header file). We do this not because it's better than the second approach, but because it's easier. Keep this in mind, and don't be afraid to change the code on the disk to suit your needs. To make it easier to switch between the two approaches, we will use the following strategy: only the class template definitions and function template prototypes will be given directly in the header files. The class template methods will be placed in special files with .mth extensions. (Here, mth stands for methods.) These .mth files will then be included in the header files via #include statements. Figure 3.3 illustrates this idea. You can easily take the #include statements out of the header files and rearrange the template code any way you wish.
The other problem we mentioned--(the inability of the compilers to automatically instantiate the correct template) may occur in some C++ compilers with early implementations of templates. (Borland C++ 3.0 and 3.1 are examples.) In some cases, you'll get linker errors saying that a function cannot be found, even though there is a template for it. In cases like this, the best strategy is to go ahead and declare a template function prototype with the correct parameters. Here is an example that uses the Array templates from Chapter 4 :
This is often enough to help out the compilers. See the code on disk for Chapter 4 for numerous examples of this.
In case your compiler doesn't support templates, we'll now show you how to turn the template code in this book into non-template code. The technique involves using a good editor that has search and replace capabilities. We'll use the constructor for the stack template as an example and turn it into a constructor that's specific for compound numbers. Similar techniques can be used for normal function templates, as well as complete template classes. Here is the original definition of the stack template constructor:
Follow these basic conversion steps:
1. Make a copy of the template to be modified. Then, remove all occurrences of the template prefix (for instance, template<Parm1, Parm2, . . .>) from this copy. The code provided in this book always keeps the prefix on a separate line, making this easy to do: Just delete the line that the prefix is on.
2. Remove all occurrences of <Parm1, Parm2, . . .> by using search and replace. (That is, replace the string with nothing.) For example:
3. Replace each occurrence of the template parameter names with the specific names you would like to use. For instance, we'll replace every occurrence of TYPE with Compound. Now our stack template looks like the following:
4. Replace all occurrences of the class name with a unique name. You can do this by using the template parameters in the name. For example, you could add the suffix _Compound:
Note that this search and replace process is fairly easy for simple templates, but when you start working with complicated template schemes (such as those that have multiple parameters or that mix in inheritance), it can get tricky.
It's possible to define templates using macros. In fact, many early C++ implementations had a generic.h header that provided a standard way to define templates with macros. However, this approach involves using multiple-line macros, a tedious and extremely error-prone technique. Your best bet is to find a compiler that directly supports templates.
Data structures such as arrays and linked lists are often called containers, because they are used to store, or contain, other objects. Stacks and trees are also examples of containers. Because containers are so widely used, it's worthwhile to look at some issues that are common to all containers. There are two fundamental issues:
A container can hold objects that are all the same type, or it can hold objects of different types. The former is called a homogenous container, the latter is called a heterogenous container.
An array is an example of a homogenous container, since by definition it is a sequence of objects of the same type. Strictly speaking, all containers in C++--such as linked lists, trees, and so forth--are homogenous. That's because C++ is a statically typed language. For instance, list nodes can only store one type of data, as in the following character list node:
If this is true, how can we get heterogenous containers? The answer for C++ is that we can't--at least not exactly. However, we can emulate hetorogenous containers by storing pointers to objects in the containers, rather than the objects themselves. We could make our list node general purpose by changing the char type to a void pointer, as in:
The same idea can be used with arrays:
By using void pointers, we can use any type of data with our containers. While this is certainly the ultimate in flexibility, the downside is that we must be very careful that an object taken out of the container is given the same type it had when it went into the container. Safe type casting becomes a major concern. For example:
One way to tame unruly containers that store object pointers is to allow only certain types of pointers to be stored. For example, we can use base class pointers rather than void pointers. Because of the special relationship between base and derived classes, the base class pointers can point not only to base class objects but also to objects of any classes derived from the base. It can't, however, point to other types of objects (without unscrupulous typecasts, that is). It's actually quite useful and intuitive to restrict the type of object pointers being stored to those that belong to some hierarchy.
A perfect example of this approach is a stack of window objects. We might have different types of windows--such as dialog boxes, menus, and browsing windows--all derived from the same window root class. Figure 3.4 illustrates this setup, where we've used the class names Window, Dialog, Menu, and Browser. A window stack is used to define the overlapping order of the windows as they appear on screen. The stack might be defined and used as follows:
The last statement shows that, even with this setup, we don't eliminate type casting problems. Because generic Windows pointers are used, when we pop the current window off the stack, we won't know what type of window we just obtained. If we guess wrong, the results could be catastrophic. We'll have more to say about this later in the chapter.
A problem immediately surfaces whenever we store an object in a container indirectly, through a pointer: Who owns the object? Who is responsible for making sure the object gets destroyed when it's no longer needed? Should it be the container, or the entity that initially created the object? Aliasing problems abound because we're using pointers to the object. It's safer to simply store a copy of the object. However, by storing a copy, we may lose the flexibility of storing different types of data. And if the objects are large, we may waste a lot of space. Here, the tradeoff is one of space versus flexibility.
Containers that share objects with other entities are said to have share semantics. Containers that store copies of objects (even if they're the only copies) are said to have copy semantics. Figure 3.5 illustrates this difference.
Containers with share semantics always use pointers or references to objects. Containers with copy semantics typically do not. But it's interesting to note that containers with copy semantics can use pointers. Consider the following code:
As long as each element of the array is the only entity using the object being pointed to, no sharing occurs. Thus, the array a can certainly be said to have copy semantics. You won't normally see pointer arrays with copy semantics used directly like this, but it can occur quite often in classes. Consider the following WindowManager class, which handles the creation and deletion of the objects it stores.
Sometimes, you'll want a container class to manage the objects for you. Sometimes you won't. To build in this flexibility, you might store a flag in the container. The flag indicates who is to own the objects: the container or something outside the container. This "ownership" flag can be set at runtime when the container is constructed.
To provide even more flexibility, you might let each object decide who owns it. For instance, an ownership flag could be stored in each object. When an object is passed to a container, the ownership flag can be set to indicate whether the object should be deleted when the container no longer needs it.
Generalizing further, you can store a counter in each object. The counter gets incremented and decremented when containers hold and let go of the objects. Counters such as this are called reference counts. When an object's reference count goes to zero, it can safely be destroyed, since no other object points to it. We'll be using reference count schemes throughout the book.
It's possible to abstract the notion of container classes into what are called collection classes. While a container class directly uses a specific storage mechanism--such as an array, linked list, or tree--with a collection class, that underlying storage mechanism is kept hidden. Collection classes were made popular by the Smalltalk language, and many C++ libraries have attempted to emulate Smalltalk-like collection classes.
The following Bag class is an example of a collection class:
A Bag is probably the ultimate collection class. You can "throw" objects into a bag and then retrieve them using a key. Ordering and sequencing are not concerns. Of course, you can have collections that are ordered or sequenced. For instance, you might have a SortableCollection class, derived from a SequencedCollection class.
Most collection classes are implemented so that they have share semantics and are by nature heterogenous. Indeed, that's where they get their power. To mitigate the aliasing and type casting problems caused by using share semantics, many collection classes only allow you to store objects derived from a single root class. In such a single-rooted hierarchy, the root class defines common features that all objects are to have. For example, each object might have the attributes shown in Table 3.1.
The following Object class represents a simple base class of a single-rooted hierarchy. It implements all of the features of Table 3.1, except reference counting:
Note that this class is abstract, since it uses pure virtual functions. Some of these functions perform important runtime type checking operations. For instance, the ClassId( ) function is supposed to return a unique integer code representing the actual type of the object. The IsSameTypeAs( ) function uses this:
Note that the Object class does not specify where the Id is stored or how it is derived. That way, no space needs to be taken in the objects for the Id. However, you don't get something for nothing; to avoid storing the Id, we must use a virtual function, and that means each object must have a virtual function table pointer. (The objects probably will have virtual functions anyway.)
Each Object is required to provide a comparison function. For example, the IsEqualTo( ) virtual function is used by the overloaded operator==( ) function, as follows:
Note that, for two objects to compare equal, they must be of the same type, which is checked at runtime. This is one example of how a single-rooted hierarchy can alleviate type casting problems.
Let's look at the type casting issue further. Suppose we want to store a collection of bank accounts. For simplicity, we'll assume two possible types of accounts: checking and savings. Furthermore, we'll store these accounts using an array. The following code sketch shows how we might go about this:
These classes are both derived from Object and, in particular, override the type management functions as follows:
The ClassId( ) functions are the most interesting, since they return a constant storing a unique code for each class. These codes must be defined somewhere:
Where should these constant definitions go? How do we ensure that two classes don't get the same Id? Unfortunately, C++, being a statically typed language, isn't really set up for runtime type checking. (Future versions may provide this feature, though.) We'll lay aside these problems for now, and show how the runtime type checking can come in handy. The following code sketch shows how an array of accounts can be built. Then, for each savings account, we pay the interest due on the account. We use runtime type checking to determine whether an account is a savings account.
A complete running program for the checking account objects is given on disk in the files object.h, object.cpp, and objtst.cpp.
In this chapter, you've seen some strikingly different ways to design data structures in C++. Which way is best? There really isn't one. Each technique can be very useful, given the right application. However, one approach will be used more frequently in this book than the others. Specifically, we'll use concrete data types, and we'll define these types using templates. The reason for doing this is threefold:
The second point is an important one. Concrete data types provide a good match for one of the main design philosophies behind C++, which is to allow code to be written in an encapsulated, object-oriented style--without sacrificing efficiency.
In contrast, the single-rooted hierachy, collection class approach isn't as well suited to C++. Many Smalltalk-like libraries have been built for C++, without considering whether these libraries make any sense in C++. Using these libraries often results in slow and bloated code. Also, the otherwise worthy notion of collection classes is sometimes abused by overzealous designers who don't stop to think about what they are creating. A case in point: some class libraries allow collections to be indexed as though the collection were an array, when in fact a linked-list or tree is being used! It's best not to use a data structure in unnatural ways such as this. Use a data structure for the purpose it was designed.
On the other hand, we don't want to imply that the single-rooted hierarchy approach is bad. Quite the contrary. Single-rooted hierarchies are ideal for applications like graphical user interfaces. Indeed, such interfaces were a major influence on the design of Smalltalk. But, aside from applications like these, you may want to consider whether a single-rooted hierarchy really makes sense.
Rational and Compound Numbers
class Rational{private:
long n, d; // Numerator and denominator
public:
// Constructors and assignment
Rational( );
Rational(long u);
Rational(long u, long v);
Rational(const Rational &r);
Rational &operator=(const Rational &r);
// Stream I/0 operators
friend istream &operator>>(istream &s, Rational &r);
friend ostream &operator<<(ostream &s, const Rational &r);
// Arithmetic operators that modify their operand
Rational operator++(int); // Postfix
Rational operator-(int); // Postfix
Rational &operator++( ); // Prefix
Rational &operator-( ); // Prefix
Rational &operator+=(const Rational &r);
Rational &operator-=(const Rational &r);
Rational &operator*=(const Rational &r);
Rational &operator/=(const Rational &r);
// Arithmetic operators resulting in new object
Rational operator-( ) const;
Rational operator+( ) const;
friend Rational operator*(const Rational &a, const Rational &b);
friend Rational operator/(const Rational &a, const Rational &b);
friend Rational operator+(const Rational &a, const Rational &b);
friend Rational operator-(const Rational &a, const Rational &b);
// Comparison operators
friend int operator==(const Rational &a, const Rational &b);
friend int operator!=(const Rational &a, const Rational &b);
friend int operator<(const Rational &a, const Rational &b);
friend int operator<=(const Rational &a, const Rational &b);
friend int operator>(const Rational &a, const Rational &b);
friend int operator>=(const Rational &a, const Rational &b);
// Other helper functions
...
};
class Compound {private:
long w; // Whole number part
Rational f; // Fractional part
public:
// Member functions, similar to those for the Rational class
...
};

ABSTRACT DATA TYPES
class AbsChStk { // An abstract character stack classprivate:
// Prevent copy constructing and assignment
AbsChStk(const AbsChStk &) { }void operator=(const AbsChStk &) { }public:
AbsChStk( ) { }virtual ~AbsChStk( ) { }virtual int Push(const chart &c) = 0;
virtual int Pop(char &c) =0;
virtual int IsEmpty( ) = 0;
virtual int IsFull( ) = 0;
};
class ChArrStk : public AbsChStk { } // Derive array versionclass ChListStk : public AbsChStk { } // Derive list versionvoid Doit(AbsChStk *pstk)
{pstk->Push('x'); // Calls virtual function}
ChArrStk my_arr_stk;
ChListStk my_list_stk;
...
// Choose stack implementation at runtime:
Doit(&my_arr_stk); // Use array version
...
Doit(&my_list_stk); // Use list version
AbsChStk *p, *q;
p = q; // AbsChStk::operator=( ) called
Figure 3.1 Stack classes created with single versus multiple inheritance.
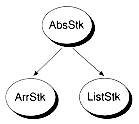
(a) Single Inheritance
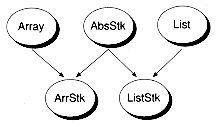
(b) Multiple Inheritance
Using Single Inheritance
class ChArrStk : public AbsChStk {private:
int sz, top; // Dimensioned size and top of stack
char *data; // Stack data
void Copy(const ChArrStk &s);
public:
ChArrStk( );
ChArrStk(const ChArrStk &s);
ChArrStk(int n);
virtual ~ChArrStk( );
ChArrStk &operator=(const ChArrStk &s);
virtual int Push(const char &c);
virtual int Pop(char &c);
virtual int IsEmpty( );
virtual int IsFull( );
};
ChArrStk: ChArrStk(int n)
{data = new char[sz = n] ;
top = 0;
}
ChArrStk::~ChArrStk( )
{delete[] data ;
}
int ChArrStk :: Push(const char &c)
// Pushes c onto the stack, if it can. Returns
// 1 if successful. Returns 0 if stack was
// full coming in.
{if (!IsFull( )) {data[top++] = c ;
return 1 ;
}
else return 0 ;
}
int ChArrStk::Pop(char &c)
// Pops element from the stack, and returns
// its value in c. Returns 1 if stack wasn't
// empty before pop; otherwise, returns 0.
{if (!IsEmpty()) {c = data[-top ;
return 1;
}
else return 0;
}
int ChArrStk::IsEmpty( ) { return top == 0; }int ChArrStk: IsFull( ) { return top == sz; }class ChListStk : public AbsChStk {protected:
int out_of_memory;
ChNode *head ;
void Copy(const ChListStk &s);
public:
ChListStk( );
ChListStk(const ChListStk &s);
virtual ~ChListStk( ) ;
ChListStk &operator=(const ChListStk &s);
void Clear( );
virtual int Push(const char &c);
virtual int Pop(char &c);
virtual int IsEmpty( );
virtual int IsFull( );
};
int ChListStk::Push(const char &c)
// Pushes c onto the stack, if it can. Returns
// 1 if successful; returns 0 if not.
{ChNode *t = new ChNode(c, head);
if (t) {head = t;
return 1;
}
else {out_of_memory = 1;
return 0;
}
}

Using Multiple Inheritance
class ChListStk : public AbsChStk, private ChList {private:
void Copy(const ChListStk &s);
public:
ChListStk( );
ChListStk(const ChListStk &s);
virtual ~ChListStk( );
ChListStk &operator=(const ChListStk &s);
virtual int Push(const char &c);
virtual int Pop(char &c);
virtual int IsEmpty( );
virtual int IsFull( );
};
int ChListStk::Push(const char &c)
{return AddtoFront(c); // Calls ChList::AddToFront()
}
int ChListStk::Pop (char &c)
{return RmvHead(c); // Calls ChList::RmvHead()
}
int ChListStk::IsEmpty( ) { return ChList::IsEmpty( ); }int ChListStk::IsFull( ) { return ChList::IsFull( ); }
PARAMETERIZED TYPES (TEMPLATES)
A Parameterized Stack Class
class ChStack {private:
char data[32];
int top;
public:
ChStack( ) { top = 0; }void Push(const char &c) { data[top++] = c; }void Pop(char &c) { c = data[-top]; }}:
typedef char TYPE;
const int SIZE = 32;
class Stack {private:
TYPE data [SIZE];
int top;
public:
Stack( ) { top = 0; }void Push(const TYPE &c) { data[top++] = c; }void Pop(TYPE &c) { c = data[-top]; }};
template<class TYPE, int SIZE>
class Stack {private:
TYPE data[SIZE];
int top;
public:
Stack( ) { top = 0; }void Push(const TYPE &c) { data [top++] = c; }void Pop(&TYPE &c) { c = data [-top]; }};
Stack<char, 32> mystack;
Stack<int, 100> yourstack;
Stack<ChList, 42> exoticstack;
typedef Stack<ChList, 42> StackOfLists;
StackOfLists exoticstack;
class Stack_ChList_42 {private:
ChList data[42];
int top;
public:
Stack_ChList_42( ) { top = 0; }void Push(const ChList &c) { data[top++] = c; }void Pop(ChList &c) { c = data[-top]; }};
typedef Stack<char, 4> QuadStack;
typedef Stack<char, 6> HexStack;
Stack<char, 4> mystack;
Stack<char, 2+2> yourstack;
template<class TYPE>
class Stack {private:
TYPE *data;
int top;
public:
Stack(int sz) { top = 0; data = new TYPE[sz]; }~Stack( ) { delete[] data; }void Push(const TYPE &c) { data[top++] = c; }void Pop(TYPE &c) { c = data[-top]; }};
Stack<char, 42> mystk; // Using static allocation
Stack<char> yourstk(42); // Using dynamic allocation
void f(int sz)
{Stack<char, sz> mystk; // Can't do; sz isn't constant!
Stack<char> yourstk(sz); // OK
}

Function Templates
template<class TYPE>
Stack<TYPE>::Stack(int sz)
{top = 0; data = new TYPE[sz];
}
template<class TYPE>
void Stack<TYPE>::Push(const TYPE &c)
{data[top++] = c;
}
Stack<TYPE>::Stack(int sz)
void Stack<TYPE>::Push(const TYPE &c)
template<class TYPE>
void InsertionSort(TYPE *a, int n)
{int i, j;
TYPE item_to_sort;
for(i = 1; i < n; i++) {item_to_sort = a[i];
j = i;
while(item_to_sort > a[j-1]) {a[j] = a[j-1];
j -= i;
if (j == 0) break;
}
a[j] = item_to_sort;
}
}
Compound arr[10];
...
InsertionSort(arr, 10);
void InsertionSort_Compound(Compound *a, int n)
{...
Compound item_to_sort;
for(...) {...
while(item_to_sort < a[j-1]) {...
}
...
}
}
Overriding Function Templates
char names[10][80]; // An array of 10, 80 byte character strings
InsertionSort(names, 10);
while(item_to_sort < a[j-1]) {class String {private:
char *text;
...
public:
String(char *s);
friend int operator<String &a, String &b);
...
};
String::String(char *s)
{text = strdup(s);
}
...
int operator<(String &a, String &b)
{return strcmp(a.text, b.text) < 0;
}
...
String strings[3] = { // Declare array of stringsString("frosty"), String("morning"), String("cold")};
InsertSort(strings, 3); // Sort the strings
void InsertionSort(char **a, int n)
{int i, j;
char *item_to_sort;
for(i = 1; i < n; i++) {item_to_sort = a[i];
j = i;
while(strcmp(item_to_sort, a[j-1]) > 0) {a[j] = a[j-1];
j -= 1;
if (j == 0) break;
}
a[j] = item_to_sort;
}
}
Restrictions on Template Functions
template<class TYPE> void f(int v); // Illegal: TYPE not used
template<class TYPE, int SZ> void g(TYPE *a); // Illegal: SZ not used
Stack_TYPE(Stack<TYPE> *this, int sz);
Combining Templates and Inheritance
class RecFile {protected:
enum io_dir { f_read, f_write };fstream fs; // Embedded fstream object
int recsize; // Record size in bytes
long curr_rec; // Current record (count by zero)
char name[80]; // Name of the file
int IO(io_dir dir, void *data, int nrecs, long recno=-1);
public:
RecFile(int rsize = 1); // Default to character I/O
~RecFile( );
virtual int Open(char *fname, int omode);
virtual int Close(void);
int IsOpen( );
int State( );
long Seek(long recno, io_dir which, ios::seek_dir mode=ios::beg);
};
template<class TYPE>
class FileOf : public RecFile {public:
FileOf( ) : RecFile(sizeof(TYPE)) { }int Read(TYPE &data, long recno = -1) {return IO(f_read, &data, 1, recno);
}
int Write(TYPE &data, long recno = -1) {return IO(f_write, &data, 1, recno);
}
};
FileOf<Compound> myfile; // Declare file of compound number records
myfile.Open("test.fil", ios::in | ios::out | ios::trunc);Compound x;
. . .
myfile.Write(x, 17); // Write x to record 17
myfile.Read(x, 1); // Read record 1 into x
Figure 3.2 A template-based family of classes.

Compiler-Dependent Template Issues
Like inline functions, the template definitions must be available when a template declaration is seen, so that the compiler can expand the template and generate the specific code. It's easy to produce multiple template instantiations, which can cause linker errors. Some compilers aren't able to automatically instantiate the correct templates in complex cases (such as when the templates are part of a class derivation hierarchy.)void PrtArray(DVarray<int> &a); // Declare template function prototype
Figure 3.3 File organization for templates used in this book.

Getting Along without Templates
template<class TYPE>
Stack<TYPE>::Stack(int sz)
{top = 0; data = new TYPE[sz];
}
Stack<TYPE>::Stack ===> Stack::Stack
Stack::Stack(int sz)
{top = 0; data = new Compound[sz];
}
Stack_Compound::Stack_Compound(int sz)
{top = 0; data = new Compound[sz];
}
CONTAINERS
Can you have different types of data in the container? Who owns the data in the container?Homogenous versus Heterogenous Containers
struct ChNode {char data; // Node data is a character
ChNode *next;
};
struct GNode {void *data; // Points to data allocated elsewhere
ChNode *next;
};
void *general_array[42];
class Container { ... }; // Some type of container classint i;
Compound c;
Container w;
w.PutAt(1, &i); // Store objects in container
w.PutAt(2, &c);
int j = *((int *)w.GetAt(2)); // Wrong type casts!
Compound d = *((Compound *)w.GetAt(1);
class WindowStack {private:
Window *contents[42]; // Allows 42 window object pointers
...
public:
...
int Push(const Window *w);
int Pop(const Window *&w);
};
WindowStack wstk;
Window *top;
Dialog d;
Browser b;
wstk.Push(&d);
wstk.Push(&b);
wstk.Pop(top);
top->Remove( ); // Call virtual Remove( ) function
wstk.Pop(top);
((Browser *)top)->LoadFile( ); // OOPS! Wrong cast
Figure 3.4 A window class hierarchy.

A Question of Ownership
// An array of pointers with copy semantics
int *a[2];
a[0] = new int(42); // Only a[0] has access to new object
delete a[0]; // Only a[0] destroys the object
a[1] = new int(17); // Only a[1] has access to new object
delete a[1]; // Only a[1] destroys the object
class WindowMgr {private:
Stack<Window *> wstk;
public:
...
CreateDialog(int w, int h) { wstk.Push(new Dialog(w, h)); }CreateBrowser(int w, int h) { wstk.Push(new Browser(w, h)); }RmvWindow(int id) { delete wstk[id]; FixupStack(); }};
Figure 3.5 Copy and share semantics.

Collection Classes and Single-Rooted Hierarchies
class Bag {protected:
// Some way of containing objects defined here
...
public:
// Functions to add and remove objects from the bag
int Add(Object *x);
int Find(char *objkey, Object *x);
int Remove(char *objkey);
...
};
class Object {protected:
virtual int IsEqualTo(const Object &fo) const = 0;
public:
virtual ~Object( ) { }virtual const char *Name( ) const = 0;
virtual int ClassId( ) const = 0;
virtual ostream &Print(ostream &s) const = 0;
int IsSameTypeAs(const Object &x) const;
friend int operator==(const Object &a, const Object &b);
friend int operator!=(const Object &a, const Object &b);
friend ostream &operator<<(ostream &s, const Object &x);
};
int Object::IsSameTypeAs(const Object &x) const
// Same type of object?
{return ClassId( ) == x.ClassId( )};
}
Table 3.1 Typical attributes of an object from a single-rooted hierarchy.
Attribute Purpose
Class name Debugging aid
Class Id Runtime type checking
Comparison functions General sorting purposes
Reference count Memory management
Printing function Debugging aid, reporting
int operator==(const Object &a, const Object &b)
{return a.IsSameTypeAs(b) && a.IsEqualTo(b);
}
//
// Checking account class
//
class CheckAcct : public Object {
protected:
float balance;
virtual int IsEqualTo (const Object &x) const;
public:
CheckAcct( );
CheckAcct(float starting_balance);
CheckAcct(const CheckAcct &ca);
CheckAcct &operator=(const CheckAcct &ca);
virtual float Deposit(float amt);
virtual float Withdraw(float amt);
float Balance( ) const;
// Object management functions
virtual const char *Name( ) const;
virtual int ClassId( ) const;
virtual ostream &Print(ostream &s) const;
};
//
// Savings account with interest
//
class SavingsAcct : public CheckAcct {
protected:
float rate; // Interest rate
float accum_interest; // Interest last paid out
virtual int IsEqualTo(const Object &x) const;
public:
SavingsAcct(float starting_balance=0.0, float r = 0.05);
SavingsAcct(const SavingsAcct &ca);
SavingsAcct &operator=(const SavingsAcct &ca);
void PayInterest( );
float InterestPaid( );
// Object management functions
virtual const char *Name( ) const;
virtual int ClassId( ) const;
};
int CheckAcct::IsEqualTo(const Object &x) const
// ASSUMES x is a checking account object. (That's why
// this function is protected.)
{return ((CheckAcct &)x).balance == balance;
}
const char *CheckAcct::Name() const
{return "Checking Account";
}
int CheckAcct::ClassId() const
{return CheckAcctType;
}
int SavingsAcct::IsEqualTo(const Object &x) const
// ASSUMES x is a savings account object. (That's
// why this function is protected.)
{return ((SavingsAcct &)x).balance == balance;
}
const char *SavingsAcct::Name( ) const
{return "Savings Account";
}
int SavingsAcct::ClassId( ) const
{return SavingsAcctType;
}
// Define class Id's for all types used
const int CheckAcctType = 1;
const int SavingsAcctType = 2;
const int num_accts = 2;
CheckAcct *MyAccts[num_accts];
MyAccts[0] = new SavingsAcct(1000.0);
MyAccts[1] = new CheckAcct(500.0);
// Pay interest on all accounts
for (i = 0; i<num_accts; i++) {if (MyAccts[ i ]->ClassId( ) == SavingsAcctType) {// Only now is type cast safe
SavingsAcct *acct = ((SavingsAcct *)MyAccts[ i ]);
acct->PayInterest( );
}
}

SUMMARY
Concrete data types are ideal for this book, since they allows us to show direct designs of a data structure Concrete data types are usually more efficient than the other approaches, and in many ways provide a "better match" for C++'s capabilities and philosophy By using templates, we can show direct designs that are still general enough to be used for many types of data