


One of the great attractions of C++ is the breadth and scope of programs that can be expressed in the language. Since C++ inherits virtually all the characteristics of C, you have the ability to code at a fairly low level, almost at the level of assembly language. At the same time, C++ allows you to express your designs at a fairly high level by using classes, constructors, destructors, and operator overloading. You can select the desired level of abstraction you would like to work with and, in fact, mix both high-level and low-level code together. Few other languages allow these combined capabilities.
C, Pascal, FORTRAN, and assembly are, for the most part, low-level languages because they can't be used to directly express high-level concepts. However, these languages have advantages, since they can produce code that's quite efficient. On the other hand, languages such as Lisp, Smalltalk, and Prolog are very high level, and it can be a joy working with the abstractions these languages allow. Unfortunately, these languages often produce very inefficient code. If you want to use their high-level constructs, you pay a high price. There needs to be some middle ground.
C++ provides that middle ground. When you want efficiency, you can have it. When you want high-level design, you can have that, too. Figure 2.1 illustrates this point. Of course, you can't always have both of these attributes at the same time. There is almost always a tradeoff between efficient code and high-level code. The important point is that C++ allows you to control this tradeoff.
Consider one of the main philosophies that went into creating C++: You should never have to pay for a feature you aren't using. This can be summed up another way:
C++: As high level as desired, but no higher.
This means you can pick the level of abstraction you would like to use, but not pay for any higher abstractions. Great care went into the design of C++ to allow this. The designers were very concerned about efficiency issues, but also wanted the language to be much more expressive than C in specifying higher-level concepts. Inline functions are a good example. Used properly, inline functions aid in the encapsulation of the inner workings of a data type, without causing the overhead normally associated with functions.
It is highly recommended that you follow C++'s philosophy when designing your data structures and algorithms. Use as high a level of abstraction as you need, but don't get carried away and try to create the ultimate in general-purpose code. Don't try to create Smalltalk-like data structures unless that's your goal. As we pointed out in Chapter 1, simpler designs are often easier to debug and maintain than general designs, and will most likely be more efficient.
The most important feature of C++, especially in terms of data structure design, is the class construct. It's the class construct that allows you to encapsulate your data structures, hiding the inner workings. It's also the class construct that allows you to use inheritance, which is a powerful way of abstracting and reusing your code. Since classes are such a central feature, it's important to know what constitutes a good class design. Almost every non-trivial, well-designed class has the following attributes:
1. Encapsulated, or hidden, members
2. A default constructor
3. A copy constructor
4. An overloaded assignment operator
5. A virtual destructor
These attributes are illustrated in Figure 2.2. To demonstrate these five desired class attributes, let's take a look at a sample Image class. This class is used to create objects that store and display bitmaps. The bitmaps are allocated dynamically. The class definition is:
The code for this Image class can be found on disk in the file ch2_1.cpp.
You can see that the Image class has all five of the attributes we've just mentioned. Please note that you are not required to use all of these attributes in your classes. In fact, don't include them if they don't make sense. Rather, when you see a class that doesn't have all of these attributes, it should signal a warning to you, and you should ask yourself why the class doesn't have them.
There are two access sections in the sample Image class: a protected section and a public section. The protected section contains the inner workings of an Image object that are meant to be hidden from users of the Image class. The public section defines the interface to the class--that is, those members that are meant to be used directly. Quite often, the private and protected members of a class are predominately data members, whereas the public members are predominately functions.
Recall from your C++ studies that protected members are private to all outside users of a class, except for any classes derived from the class. We could have made the protected members of Image private, and disallowed even derived classes from accessing them. Some people argue that protected access should rarely be used, if at all. They even go so far as to say that the very way derived classes are implemented violates the principles of encapsulation. We won't get embroiled in such controversies here. Instead, we'll use the following convention:
Whenever a class is designed to be a base class, with inheritance in mind, the hidden members of the class will be made protected. If the class isn't to be a base class, the hidden members will be made private.
It is up to you to determine whether you wish to follow this convention for your own classes. Don't be afraid to use your own judgment.
We've chosen to place all the data members of the Image class in the protected section, along with the following function, which is used to copy one bitmap into another:
The Copy( ) function is used by several other functions in the class, and thus helps reuse some common functionality in the class. Functions like this are typical, and are sometimes called helper functions. Note that Copy( ) assumes that the bitmap isn't already allocated. Thus, it wouldn't be safe for this function to be used arbitrarily. For that reason, we've made it hidden. Only other member functions of the class have access to Copy( ), and they presumably will call it in a safe manner.
The Image class has the following default constructor:
Default constructors are so-named because they are used whenever a constructor must be called implicitly, such as when declaring an array of objects. A default constructor doesn't require any arguments when called, meaning that it either has no arguments or that all of its arguments have default values.
What should a default constructor do? Most people design their default constructors to create a "null" object, whatever that means. (It depends on what the object is.) Quite often, it means setting all data members to zero. Here, we've chosen to create an image that has an empty bitmap.
If you don't declare a default constructor, one will be generated automatically by the compiler, but the data members will not be initialized by this generated constructor. Thus, it behooves you to define your own default constructor.
Copy constructors are used whenever an object is to be created and initialized as a copy of some other existing object of the same type. For example, copy constructors are called whenever an object is a parameter passed by value to a function, or when an object is the return value of a function. This copy construction approach is illustrated in Figure 2.3.
In these cases, the constructor is called implicitly to make a copy of the parameter being passed in or the object being returned. Here is the copy constructor for the Image class. Note how the helper function Copy( ) is called:
To be a copy constructor, a constructor must be callable by passing a single argument. That means it must either have only one argument or all arguments except the first must have default values. The first argument must be of the same class to which the constructor belongs, and must be passed by reference.
Note If you don't pass the first argument of a copy constructor by reference, you'll end up with recursive calls to the constructor that will go on indefinitely, locking up your program.
The Image( ) copy constructor meets these criteria. Note that we pass not just a reference to an Image object to the constructor, but a reference to a constant object:
We could have also used:
In a later section, we'll discuss why it's preferrable to use the const modifier in cases like this.
If you don't declare a copy constructor, the compiler will generate one automatically for you. This generated constructor will do a member-wise copy. That is, it will copy each data member, one by one. If a member is a pointer, then only the value of the pointer is copied, not what the pointer points to. This can lead to serious memory management problems, because two objects can end up with members pointing to the same dynamic storage locations, a situation called aliasing. This becomes a problem when it's time to free up the dynamic storage, since both objects will attempt to free the same memory locations, wreaking havoc on the heap.
Aliasing can be avoided at copy-construction time by defining your own copy constructor and having that constructor make copies of any dynamic data being pointed to, rather than just copying the pointers. Our Image( ) copy constructor does just that by calling the Copy( ) helper function.
We've overloaded the assignment operator for the Image class as follows:
The overloaded assignment operator, operator=( ), performs much the same function as the copy constructor by allowing one object to be copied into another. One crucial difference is that, unlike the copy constructor, operator=( ) assumes that the target object is already built, and already has a bitmap allocated. Thus, operator=( ) must first delete the allocated bitmap, so that Copy( ) can allocate a new one of the proper size.
The previous paragraph points out the critical difference between initializing an object and assigning an object. Copy constructors are used whenever an object is created and initialized to be a copy, whereas assignment operators are used when assignment takes place. While it's usually fairly obvious which is occurring, it isn't always so. Consider the following code:
The last two statements look almost identical, but they do very different things. The first creates and initializes picture to be a copy of snapshot; the second assigns a copy of the snapshot image to the existing picture object. The first statement uses the copy constructor; the second statement uses the overloaded assignment operator. The tipoff is that the first contains a type declaration, using the type Image; the second doesn't. Thus, we know that the first statement is actually a call to a constructor.
Like the copy constructor, the operator=( ) function takes a single argument that's a reference to a constant Image object. The const modifier is used for the same reason as it is in the copy constructor (discussed later). The object is passed by reference for efficiency's sake, and for notational convenience. Contrast the following two operator=( ) functions. One uses a reference parameter, while the other uses a pointer parameter:
You are not required to use pass by reference for overloaded assignment operators like you are for copy constructors, but as you can see, it's a good idea.
We show the assignment operator as returning a reference to the object that was the target of the assignment. You are not required to do this, but it's often done to allow assignments to be chained together, as in the following:
This would actually result in the following calls:
If you don't overload the assignment operator for a class, the compiler will subsititute member-wise copying whenever assignments occur between two objects of that class. As is the case with copy constructing, this situation can result in aliasing. Thus, it's a good idea to include an overloaded assignment operator, especially when dynamic storage is being pointed to by the object.
To properly de-allocate the bitmap data of an image, the Image destructor is used:
Notice in the class definition that the destructor is virtual. This is done for safety reasons. For example, we'll be deriving a HideableImage class later on, which dynamically allocates some additional storage for a "backing store." This additional storage is to be used in saving what's underneath an image about to be drawn. When the destructor for HideableImage is called, we want the backing store to be freed as well as the bitmap data. It's critical that the correct destructor is called when the object is destroyed. By making the destructors virtual, code like the following will work just fine:
It's not always necessary or desirable to make a destructor virtual. For instance, if you don't plan on deriving from a class, there is no need to make any functions virtual. If you go ahead and make the destructor for the class virtual, you will cause an extra pointer to be stored in every object created from the class, thus wasting space. (This extra pointer points to a virtual function table.) The following rule of thumb will help you decide whether to use a virtual destructor:
If your class uses virtual functions, you should always include a virtual destructor, even if that destructor doesn't do anything. (The derived class destructors might need to do something.) If your class needs no virtual functions, making the destructor virtual is optional. You might want to keep it non-virtual to save space.
Note Even though destructors can and most likely should be virtual, constructors can never be virtual.
One often overlooked feature of C++ is the use of constants. Constants in C++ are more robust than they are in C. In C++, constants have local scope. That is, a constant can be safely declared (defined and allocated) in a C++ header file, without worrying about having duplicate definitions when modules are linked. This allows C++ constants to be used where macros once were in C. For example, you might have a header file like the following:
This header file can be included in more than one source file. Each source file gets its own private copies of the constants. Since these copies don't have global, external names, the linker won't complain when linking the source files.
Note For simple constants, such as integers and floating point numbers, a C++ compiler may not actually create any storage for the constants, but instead will use the values directly when needed.
In C, it would not be a good idea to include the complete declarations of constants in a header file like the one above. In C, constants have global scope, and the storage for the constants might be duplicated. You would probably use constants as in the following files:
Or, you might be tempted to use macros, saving yourself the bother of having another source file to link in:
However, the macro approach is less descriptive, since it doesn't tell you the intended type of the constants.
Constants are often used in conjunction with parameters passed by reference. When you use constants in this way, you can get safe, elegant, and efficient code. Contrast the following two functions. One passes a reference to an X object (which is presumed to be some large structure), while the other passes a pointer to an X object:
Passing by reference argument is cleaner than passing by pointer, since you don't need to take the address of the object via the & operator. However, some people object to using references this way, since it isn't obvious that the object might be modified inside the function. With the pointer method, the & operator sends a clear warning flag. Using the const modifier solves that problem for the reference argument case, since the function won't be able to modify the object. (Actually, the function can modify the object by using some clever type casting, but the programmer must consciously choose to do that.)
You will see the const X &x syntax used quite often in this book. In particular, it's considered good style to use this syntax for overloaded assignment operators and copy constructors.
Another use of the const modifier is to declare constant member functions. Ordinarily, if you declare an object to be constant, then you can't call any of the object's functions. The functions might change the internal state of the object, violating the concept of a constant object. However, if a function truly doesn't change any part of the object, you can declare the function to be constant, and the compiler will let that function be called. Here's an example:
The First( ) function can't be called for the constant object x, since it's an ordinary member function. The Second( ) function can be called, since it was a declared constant. Note that the const keyword is placed after the parameter list but before the function body.
It's a good idea to declare member functions as being constant whenever possible. Here's why:
1. Someone might decide to declare an object of the class as being constant. By handling this possibility ahead of time, you've made the class more usable.
2. The const declaration allows the compiler to perform more optimizations.
Declaring an object constant happens more than you might think, especially if you are following good coding style. For instance, suppose we added a copy constructor for the TwoNum class, and chose to use the functions First( ) and Second( ) to aid in the copying:
We could have avoided the problem here by using the members tn.a and tn.b directly. But you might not always be so fortunate in your classes.
Don't overlook using the const modifier as an aid to the compiler for optimization. Consider the following loop:
Since Second( ) is declared as a constant member function, the compiler knows that tn is not modified by the statement y = tn.Second( ). Thus, if the data members of tn are for some reason already loaded in registers, they won't need to be reloaded after the statement, making the loop more efficient. Of course, the ability of your compiler to perform such optimizations is implementation-dependent.
Inheritance is a powerful part of C++ programming. Through inheritance, which is achieved by class derivation, you can express type-subtype relationships, as well as elegantly share and reuse code common to a system of classes. We'll now continue our Image class example to derive a new type of Image class, one that allows the image to be hidden and then later restored:
The code for this class can be found on disk in the file ch2_1.cpp.
The HideableImage class adds data members to keep track of whether the image is currently showing and where. It also adds a "backing store" buffer, which keeps a copy of what was on the screen underneath the image before the image was shown. The Show( ) function is overidden to first copy to the backing store before displaying the image, and a Hide( ) function is added to allow the image to be temporarily hidden.
Like the Image class, the five attributes we've already listed are desirable for the HideableImage class. HideableImage maintains a protected section, which hides the additional variables, and it has a default constructor, copy constructor, overloaded assignment, and a virtual destructor. We'll now look at how each of these attributes is affected by the inheritance process.
Derived Class Constructors and Destructors
Derived Class Overloaded Assignments
The HideableImage class has the following constructors defined:
These constructors all have one thing in common: they call the base class constructor. The derived class default constructor calls the default base class constructor implicitly. The other derived class constructors call the respective base class constructors explicitly. In each case, the base class constructor is called before the derived class constructor executes.
The way to remember the order of constructor calls is to look at how the base class constructors are called explicitly. Their calls are placed between the constructor parameter list and the constructor body, in the member initialization list:
The placement of the member initialization list correctly suggests when the base class constructors are called.
The member initialization list can also be used to initialize members of the class (hence its name). For instance, we could modify the constructor to initialize x and y to zero, as follows:
Here, the syntax x(0), y(0), means to set x = 0, and y = 0. If x and y were objects of classes with constructors, the appropriate constructor calls would take place instead. Like the base class constructor calls, these initializations take place before the constructor body executes, so x and y get initialized before backing_store and showing. However, x and y get initialized after the call to the base class Image( ) constructor, even though they appear first in the list. That's because base class constructor calls always take place before the members of a derived class are initialized.
Except for the order in which the initializations take place, this modified constructor works the same as the original one. So why initialize members in the member initialization list? The most common reason is to initialize members that are constants, references, or objects that require constructors to be called explicitly in order to initialize them. (That is the only way these types of members can be initialized.) For instance:
In the FunnyNums constructor, a gets initialized before b (and before c), not because a is first in the initialization list, but because it was declared first in the class definition. Actually, you shouldn't rely on the order in which members get initialized, as we've done here; it's not considered good style.
Because base class constructors must be called for derived class objects, it's very rare for a derived class not to have any constructors. This would happen only if the base class has only a default constructor or no constructor at all. In this case, you don't need to declare a derived class constructor. A default one will be generated, which will call the base class constructor.
Sometimes, the derived class constructors do nothing more than turn around and call the base class constructors. It can be tedious to declare derived class constructors for cases like these. But at least the constructors can be declared inline, to hopefully avoid function call overhead.
Derived class destructors work just the opposite of derived class constructors. First, the members of the derived class are destroyed (with their destructors being called if they have any); then, the derived class constructor body is executed; and finally, the base class destructor is called, implicitly. For example, here is the HideableImage destructor:
Note that this destructor was declared virtual in the class definition, per our rules on well-designed classes.
Derived classes can have overloaded assignment operators, just as base classes do. Assignments between two derived class objects work as follows: if the derived class has an overloaded assignment, it is called. Otherwise, a member-wise copy is performed on each additional member of the derived class (that is, on those members not in the base class). If the base class has an overloaded assignment operator, it is called for the base class members; otherwise, the base class members are copied in a member-wise fashion.
The consequences of these rules are twofold:
1. If the derived class object has members pointing to dynamic storage, you'll want to overload the assignment operator for the derived class to take care of potential aliasing problems. Of course, if the dynamic data is pointed to by base class members, then presumably an overloaded base class assignment operator is already handling the problem.
2. If you do overload the assignment operator in the derived class, you must be sure that any base class overloaded assignment operator function is called, too. Or at least ensure that the actions that might have been performed by the base class assignment are performed in the derived class assignment operator function.
These two rules beg for an example. Here is the HideableImage( ) overloaded assignment operator, which embodies both rules:
Figure 2.4 illustrates the workings of the HideableImage::operator=( ) function, which must take care of two types of dynamic memory: the backing store and the bitmap stored in the base class. The storage for the backing store must be resized in case the source image has different dimensions. The bitmap storage is handled via an explicit call to the Image::operator=( ) function:
You might have noticed the parameter type used in the derived class assignment operator function:
Instead of typing the parameter as a HideableImage, we've typed it as an Image. Why have we done this? We can assign an Image object to a HideableImage object just as easily as we can assign a HideableImage object to another HideableImage object. We could have provided two overloaded operators for this, but since the code would be the same, we chose to use just one function. Because a HideableImage object can be used anywhere an Image object is used, we chose to type the parameter as an Image object. Note that, had we done the reverse,
we would not be able to assign an Image object to a HideableImage object.
Although it's a little unusual, we'll use this technique in several places--particularly with the Array classes used in Chapter 4.
Class derivation, as you've seen in the previous sections, is just one example of two classes working together to create a data structure. It's also possible for two or more cooperating classes, not related by inheritance, to work in tandem. In this section, we'll show as an example a singly-linked list implementation, which has node and list classes. In this manner, not only will you learn about setting up cooperating classes, but you'll also be introduced to the inner workings of linked lists. We won't cover all aspects of linked lists here. See Chapter 8 for a more complete discussion of them.
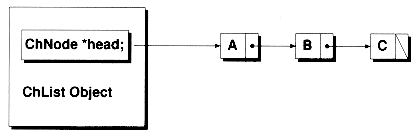
A singly-linked list consists of nodes linked in one direction. Figure 2.5 shows an example of a singly-linked list. Each node contains two parts: the data held in the node and a pointer to the next node in the list (if any).
Here's how you might define a node structure holding a single character as its data:
You'll notice we made this node a simple class, using the struct keyword instead of the class keyword. We've defined no constructors, destructors, or assignment operators. This isn't necessarily bad. For a simple structure such as this, there might not be a reason to hide any details, and the behaviors of the generated default constructor, copy constructor, and assignment functions may be satisfactory. You don't need to use all the C++ features just because they are there. We'll start with the simple ChNode definition and then dress it up later (after we've shown why you might want to do so).
The following code shows how we might construct the linked list in Figure 2.5 with ChNode objects:
In this code, we set up the links between each node by hand, using the address of the next node. The last node gets a null pointer to end the list.
Constructing lists like this can be tedious and error prone. It's also easy to lose track of which node heads the list. (In our list, node a is the head.) To solve these problems, a new class, ChList, can be introduced to handle the overall management of a list. This new class holds a pointer to the head of the list and adds nodes to the list. In essence, the ChNode and ChList classes work
together to form the actual list structure. Such classes are called cooperating classes.
Here's a simple example of a list class that allows nodes to be added to the front of the list:
Here's how we can rewrite our list construction example. Figure 2.6 illustrates the new way of representing the list.
The file ch2_2.cpp on disk shows a complete running program of the simple node and list classes.
Note how we build the list backwards because we can only add nodes to the front of the list. However, we could certainly define a function for adding nodes to the tail of the list (although it's harder). In fact, our list class is quite incomplete, because we have no way of deleting from the list, no way to walk through the contents of the list, and so forth. But before we fill out the list class, let's first see how we can improve the node class.
Here's a new ChNode class that embodies all five attributes of a well-designed class:
In our new ChNode class, we've hidden the next pointer, reasoning that the less we directly use pointers like this, the better. However, something must be able to access the next pointer, so we've made all of the ChList class a friend of ChNode, since ChList will be managing the nodes. This is a typical arrangement for cooperating classes. At least one of the classes is a friend of the other. Sometimes you may have a mutual friendship.
In contrast to the next pointer, we left data public, thinking that it might be useful for those who use ChNode to access the data directly. Using this variable directly is relatively harmless. We could, however, make it private and force it to be accessed through special access functions. Here's an example:
Would this be worthwhile? Probably not. Whenever you start coding functions like SetData( ) and GetData( ), you should stop and consider what you are doing. Using access functions in this manner isn't much different than using the data directly; and adding the functions just makes the class more complicated than it needs to be.
This isn't to say that all access functions are bad, but that perhaps you should think about how you want your design to be used at a high level. You need to ask yourself how the node objects are to be used. Here, since they are to be handled by the ChList class, it might be better for that class to handle the node data. For instance, we might design ChList to allow a user to add data to the list, without the user needing to know that list nodes even exist. Instead, we just pass ChList the data to be added, and let the list pass back any data that needs to be retrieved. This abstracts the workings of the data structure in a beneficial way. The best bet, then, is to make the data private, but leave out the access functions. Let ChList's friendly access directly manipulate the data.
The copy constructor and overloaded assignment operator functions point out another interesting design issue. What does it mean to copy a list node? If we hadn't methodically included the copy and assignment functions in the node class, we might not have ever asked that question. This proves it's always a good idea to include these two functions in your classes, because you are then forced to think more about your design.
It seems likely that we would want the node data copied, but what about the next pointer? If we allow this pointer to be copied, aliasing problems could occur. It seems best to just set the next pointer to null in the node copy. That's what our copy constructor and overloaded assignment operator do.
Actually, we might want to go further than that. We might even want to disallow nodes from being copied. We can do this by placing both the copy constructor and overloaded assignment operator in the private section of the class, as we've done here:
Statements like the following would now be illegal:
We've now put almost all of our members in the private section of the ChNode class. Why not go the full mile and make the entire class private? There are actually some valid reasons for doing so. Recall that the user of a list doesn't really need to know that list nodes exist. We can reinforce this by making the ChNode class completely private. That way, only the ChList class can use it.
The ChNode class is given on disk in the files chlist.h and chlist.cpp.
Passing Parameters Using Constant References
You'll see in the ChNode( ) general constructor that we pass in characters using a constant reference, as in
This isn't the most efficient way to pass a character, since a character is generally smaller than a reference (the latter being implemented usually as a pointer). However, the use of constant reference syntax has benefits, because it keeps the code consistent with more general cases where we might be passing much larger structures than a character. Passing parameters using constant references is a good habit to develop, even when it may not be completely warranted from an efficiency standpoint. You'll notice that we use the syntax const X &x quite often.
It's also a good idea to use a constant reference rather than a plain reference. Besides preventing the object being passed in from being accidently changed, the use of a constant reference makes it easier to pass literals. For instance, we can call the ChNode constructor as follows:
Had we declared the constructor without the const modifier,
then the preceding constructor call would have caused a temporary copy of 'x' to be made. That prevents the literal 'x' from accidentally being changed to something else inside the function. Although making a copy of the character isn't really a problem, some compilers print warnings about it, which can be quite a nuisance. (It can also be a blessing in other cases.) Using const char &d solves the whole problem.
We're now ready to complete the design of ChList, making it more robust. Here is the new definition:
We've added all the proper constructors, an overloaded assignment operator, and a destructor. We've also added a function to copy one list into another, as well as functions to clear the list by removing and freeing all nodes in the list. Also included are functions to determine whether the list is empty or whether it's full. For the latter, we say a list is full if the last AddtoFront( ) operation failed because we couldn't allocate enough memory for a list node. The out_of_memory flag keeps track of this. Here are some other functions of the ChList class:
The ChList class is given on disk in the files chlist.h and chlist.cpp.
Another way to "hide" the ChNode class, besides making all of its members private, is to simply include its class definition inside the ChList class. For example:
Nested classes work as follows: the nested class definition is hidden and the only way to access a nested class name is by qualifying it with the name of the enclosing class. For instance, here's how the default ChNode destructor is defined outside the class definitions:
The member function name ChNode( ) has two qualifications: ChList and ChNode, signifying that the function belongs to class ChNode, which belongs to class ChList. Here's another example using the overloaded assignment operator.
Note that the third use of ChNode (inside the parameter list) isn't qualified. We don't need to make this qualification because the context tells the compiler that we're referring to a ChList::ChNode object.
The nested class definition is affected by the private, protected, and public keywords in the enclosing class. We've made ChNode protected. That means only ChList member functions, or member functions of classes derived from ChList, have access to the name ChNode. Thus, only these functions can create ChNode objects. Had we placed the ChNode class definition in the public section of ChList, we could create ChNode objects on the outside, like this:
Remember that this only works if ChNode is declared in a public section. If ChNode is declared in a protected or private section, you can't access the name ChNode, even using the ChList qualification.
Nested classes have no special access to the members of the enclosing class nor do members of the enclosing class have any special access to nested classes. It's as though the two classes were defined separately. The distinction is this: the classes are nested, but not objects of the classes. The member functions of ChList can only access the public members of ChNode, and only by way of a ChNode object. There is no direct access, as you might think. Likewise, members of ChNode can only access the public members of ChList, and only through ChList objects.
Note that we made most of the ChNode members public so that ChList could easily access them through an object. However, we kept the copy constructor and overloaded assignment operator private. This way, even ChList member functions cannot accidently copy ChNode objects.
While this alternative method for declaring cooperating classes has its merits, we'll be primarily using the first method (declaring the classes separately) because it is often less confusing.
The alternative design for the ChNode and ChList classes is given on disk in the files chlist2.h and chlist2.cpp.
Figure 2.1 C++: Low level and high level.

WELL-DESIGNED CLASSES
class Image {protected:
int w, h; // Dimensions of image
char *bitmap; // Bitmap of image
int Copy(int iw, int ih, char *bm);
public:
Image( ); // Default constructor
Image(const Image &im); // Copy constructor
Image(int iw, int ih, char *bm);
virtual ~Image( ); // Virtual destructor
Image &operator=(const Image &im); // Overloaded assignment
virtual void Show(int xs, int ys);
};

Figure 2.2 Components of a well-designed class.

Encapsulation
int Image::Copy(int iw, int ih, char *bm)
// Private helper function that allocates a bitmap
// of size iw*ih, and copies the bits stored in
// bm into it.
// ASSUMES bitmap isn't already allocated.
// Returns 1 if allocation successful; 0 otherwise.
{w = iw; h = ih;
bitmap = new char[w*];
if (bitmap) { // Allocation workedmemcpy(bitmap, bm, w*);
return 1;
}
else { // Allocation failed. Set image to null.w = 0; h = 0;
return 0; // Allocation failed
}
}
Default Constructors
Image::Image()
// Default constructor to create an empty image
{w = 0; h = 0; bitmap = 0;
}
Copy Constructors
Image::Image(const Image &im)
// Copy constructor. Allocates room for bitmap
// of same size and copies im's image into it.
{Copy(im.w, im.h, im.bitmap);
}
Figure 2.3 Copy constructing during function calling.
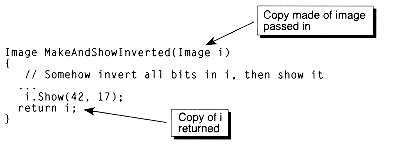
Image::Image(const Image &im);
Image::Image(Image &im);
Overloaded Assignments
Image &Image::operator=(const Image &im)
// Assignment operator. Deallocates existing
// bitmap; allocates a new one of same size.
// as im, and copies im's image into it.
{delete[] bitmap;
Copy(im.w, im.h, im.bitmap);
return *this;
}
Image snapshot(3, 5, "some bitmap");
Image picture = snapshot; // Assignment or initialization?
picture = snapshot; // Assignment or initialization?
X &X::operator=(const X &v);
Y &Y::operator=(const Y *v);
X a, b;
Y c, d;
a = b; // Clean syntax
c = &d; // Awkward syntax
Image ia, ib, ic;
ia = ib = ic;
ia.operator=(ib.operator=(ic));
Virtual Destructors
Image::~Image()
// Destructor that de-allocates bitmap. Note that bitmap
// might be null coming in, but delete() is supposed
// to handle that.
{delete[] bitmap;
}
Image *p; // Can point to Image as well as HideableImage objects
Image *StaticPicture = new Image(3, 5, "Picture bits here");
HideableImage *NowYouSeeMe = new HideableImage(8, 10, "Bits go here");
p = StaticPicture;
delete p; // Image::~Image() called
p = NowYouSeeMe;
delete p; //, HideableImage::~HideableImage() called
Constants
// trigcons.h
const double pi = 3.141592654;
const double degtorad = 0.017453292;
/* trigcons.h: Declare constants in header */
const double pi; /* extern by default */
const double degtorad; /* extern by default */
/* trigcons.c: Allocate and define constants in source file */
const double pi = 3.141592654;
const double degtorad = 0.017453292;
#define pi 3.141592654
#define degtorad 0.017453292
void DoSomething(const X &x);
void DoSomethingElse(X *x);
X myobj;
DoSomething(myobj); // Elegant, efficient, and safe
DoSomethingElse(&myobj); // Efficient, but not as elegant or safe
class TwoNum {private:
int a, b;
public:
TwoNum(int aa, int bb);
int First() { return a; } // Not a constant functionint Second() const { return b;} // A constant function};
const TwoNum x(17, 42);
int y = x.First(); // Not legal
int z = x.Second(); // Legal
TwoNum::TwoNum(const TwoNum &tn)
{a = tn.First(); // Not legal
b = tn.Second(); // Legal
}
TwoNum tn(17, 42);
for (int i = 0; i<10; i++) {int y = tn.Second( );
...
}
USING INHERITANCE
class HideableImage : public Image {protected:
int showing; // Flag indicating that image is showing
int x, y; // Location where image is showing
char *backing_store; // Bitmap of what's underneath
public:
HideableImage();
HideableImage(const HideableImage &hi);
HideableImage(int iw, int ih, char *bm);
virtual ~HideableImage();
HideableImage &operator=(const Image &im);
virtual void Show(int xs, int ys);
void Hide();
};

Derived Class Constructors and Destructors
HideableImage::HideableImage()
// Default constructor sets everything to zero.
// Note that base class constructor called implicitly
// before the body of this function executes.
{x = 0; y = 0; showing = 0; backing_store = 0;
}
HideableImage::HideableImage(const HideableImage &hi)
// Copy constructor. Note that the backing_store
// and associated flags are NOT copied. Thus, the
// base class constructor can do most of the work.
: Image(hi) // Call base class constructor explicitly
{// Initialize to "not showing," then allocate backing_store
x = 0; y = 0; showing = 0;
backing_store = new char[w*h];
}
HideableImage::HideableImage(int iw, int ih, char *bm)
// General constructor. Base class constructor does
// a lot of the work.
: Image(iw, ih, bm) // Call base class constructor explicitly
{// Initialize to "not showing," then allocate backing_store
x = 0; y = 0; showing = 0;
backing_store = new char[w*h];
}
HideableImage::HideableImage(const HideableImage &hi)
: Image(hi) // Call to base class constructor
{x = 0; y = 0; showing = 0;
backing_store = new char[w*h];
}
HideableImage::HideableImage(const HideableImage &hi)
: x(0), y(0), Image(hi)
{showing = 0;
backing_store = new char[w*h];
}
class FunnyNums {private:
const int a;
const int &b;
CompoundNum c;
public:
FunnyNums(int u, const CompoundNum &v);
};
FunnyNums::FunnyNums(int u, const CompoundNum &v)
// Initialize const a to have value u, and for reference
// b to point to a. Also, copy-construct c.
: a(u), b(a), c(v)
{// Nothing else to do
}
HideableImage::~HideableImage()
// Destructor de-allocates both the backing store
// and the shown bitmap. Note that the base class
// destructor, which de-allocates the shown bitmap,
// is called implicitly AFTER this body executes.
{Hide(); // Hide image first, if not already hidden
delete[] backing_store;
}
Derived Class Overloaded Assignments
HideableImage &HideableImage::operator=(const Image &im)
// Overloaded assignment operator. Copy just the
// image to be shown, and not the backing store.
// A new backing store will be created, though,
// with the same size.
{// We must re-allocate backing_store to new
// size. But first we must hide the image
// if it was showing.
int ss = showing; // Keep track of show status
Hide();
delete[] backing_store;
// Let base class assignment do its thing.
Image::operator=(im);
// Now, re-allocate the backing store to correct size
backing_store = new char[w*h];
if (ss) Show(x, y); // Redisplay image if necessary
return *this;
}
Image::operator=(im);
HideableImage &HideableImage::operator=(const Image &im);
Figure 2.4 Assigning hideable images.

HideableImage &HideableImage::operator=(const HideableImage &im);
COOPERATING CLASSES
Your First Singly-Linked List
struct ChNode { // Node holding a characterchar data; // Data for the node
ChNode *next; // Next node on the list
};
main()
{ChNode a, b, c;
a.data = 'a'; a.next = &b;
b.data = 'b'; b.next = &c;
c.data = 'c'; c.next = 0;
return 0;
}
Figure 2.5 A singly-linked list.

class ChList {private:
ChNode *head;
public:
ChList();
void Add(char c);
};
ChList::ChList()
// Default constructor creates an empty list
{head = 0;
}
void ChList::Add(char c)
// Add new node to the front, holding c as its data
{ChNode *p = new ChNode;
p->data = c;
p->next = head;
head = p; // New node now head of list
}
main()
{ChList mylist:
mylist.Add('c');mylist.Add('b');mylist.Add('a');return 0;
}

Figure 2.6 Alternate implementation of a singly-linked list.
An Improved List Design
// More complete node class
class ChNode {friend ChList; // Let ChList access hidden parts
private:
ChNode *next; // Hide this "detail"
public:
char data; // Keep this available to user
ChNode();
ChNode(const char &d, ChNode *n);
ChNode(const ChNode &cn);
ChNode &operator=(const ChNode &cn);
};
ChNode::ChNode()
// Default constructor
{data = 0; next = 0;
}
ChNode::ChNode(const char &d, ChNode *n)
// General constructor
{data = a; next = n;
}
ChNode::ChNode(const ChNode &cn)
// Copy constructor. Note that we don't copy the
// next pointer, but rather set it to zero.
{data = cn.data; next = 0;
}
ChNode &ChNode::operator=(const ChNode &cn)
// Assignment. Only data is copied; the next
// pointer is set to zero.
{data = cn.data; next = 0;
}
class ChNode {private:
char data;
...
public:
void SetData(char c);
char GetData();
...
};
class ChNode {friend ChList; // Let ChList access hidden parts
private:
ChNode *next; // Hide this "detail"
char data;
ChNode(const ChNode &cn); // Disallow copying
ChNode &operator=(const ChNode &cn); // Disallow assignment
public:
ChNode();
ChNode(const char &d, ChNode *n);
};
ChNode a, b;
ChNode c(a); // Illegal
b = a; // Illegal

ChNode::ChNode(const char &d, ChNode *n);
ChNode mynode('x', 0);ChNode::ChNode(char &d, ChNode *n);
class ChList {protected:
int out_of_memory;
ChNode *head;
void Copy(const ChList &c);
public:
ChList();
ChList(const ChList &c);
~ChList();
ChList &operator=(const ChList &c);
int AddtoFront(const char &c);
int RmvHead(char &c);
void Clear();
int IsEmpty();
int IsFull();
};
void ChList::Copy(const ChList &s)
// Copies the list s into this list.
// Clears the contents of this list first.
// ASSUMES the default constructor sets the
// next pointer to zero. May set out_of_memory
// flag if couldn't allocate a node.
{Clear();
ChNode *sn = s.head;
if (sn) { // Anything to copy?ChNode *tn = new ChNode;
head = tn;
while(sn && tn) {tn->data = sn->data;
sn = sn->next;
if (sn) {tn->next = new ChNode;
tn = tn->next;
}
}
if (!tn) out_of_memory = 1;
}
}
ChList::ChList(const ChList &c)
// Copy constructor
{head = 0; out_of_memory = 0;
Copy(c);
}
ChList::~ChList()
// Destructor removes all nodes from the list
{Clear();
}
ChList &ChList::operator=(const ChList &c)
// Assignment operator. Clears contents of existing
// list, and makes a copy of list c.
{Copy(c);
return *this;
}
int ChList::AddtoFront(const char &c)
// Adds a node to the front of the list,
// making a new head. Returns 1 if successful;
// otherwise, sets out_of_memory flag, and returns 0.
{ChNode *t = new ChNode(c, head);
if (t) {head = t;
return 1;
}
else {out_of_memory = 1;
return 0;
}
}
int ChList::RmvHead(char &c)
// Removes the head from the list, and set
// next node as the head. Returns 1 if there
// was a head to remove (i.e. list not empty),
// and clears memory full flag as well.
// Otherwise, a 0 is returned.
{if (head) {c = head->data;
ChNode *p = head;
head = head->next;
delete p;
out_of_memory = 0;
return 1;
}
else return 0;
}
void ChList::Clear()
// Removes all nodes from the list
{char dmy;
int r;
do {r = RmvHead(dmy);
} while(r);
}

Nested Classes
class ChList {protected:
class ChNode { // Hide the class by nesting itprivate:
ChNode(const ChNode &cn);
ChNode &operator=(const ChNode &cn);
public:
ChNode *next;
char data;
ChNode();
ChNode(const char &d, ChNode *n);
};
int out_of_memory;
ChNode *head;
void Copy(const ChList &c);
public:
...
};
ChList::ChNode::ChNode()
// Default constructor
{data = 0; next = 0;
}
ChList::ChNode & ChList::ChNode::operator=(const ChNode & cn)
{data = cn.data; next = 0;
}
ChList::ChNode mynode; // Assumes ChNode has public access
