In problems arising in computer science, mathematics, engineering, and many other disciplines we often need to represent arbitrary relationships among data objects. Directed and undirected graphs are natural models of such relationships. This chapter presents the basic data structures that can be used to represent directed graphs. Some basic algorithms for determining the connectivity of directed graphs and for finding shortest paths are also presented.
A directed graph (digraph for short) G consists of a set of vertices V
and a set
of arcs E. The vertices are also called nodes or points; the arcs could be
called directed edges or directed lines. An arc is an ordered pair of vertices
(v, w); v is called the tail and w the head of the arc. The arc
(v, w) is often
expressed by v ?/FONT> w and drawn as
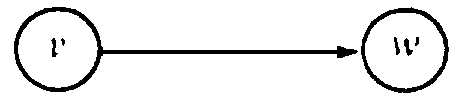
Example 6.1. Figure 6.1 shows a digraph with four vertices and five arcs.
The vertices of a digraph can be used to represent objects, and the arcs relationships between the objects. For example, the vertices might represent cities and the arcs airplane flights from one city to another. As another example, which we introduced in Section 4.2, a digraph can be used to represent the flow of control in a computer program. The vertices represent basic blocks and the arcs possible transfers of flow of control.
A path in a digraph is a sequence of
vertices v1, v2, . . . , vn,
such that
v1 ?/FONT> v2,
v2 ?/FONT> v3, . . . ,
vn-1 ?/FONT>
vn are arcs.
This path is from vertex v1 to vertex
vn, and passes through vertices v2,
v3, . . . , vn-1, and ends at vertex
vn. The
length of a path is the number of arcs on the path, in this case, n-1. As a
Fig. 6.1. Directed graph.
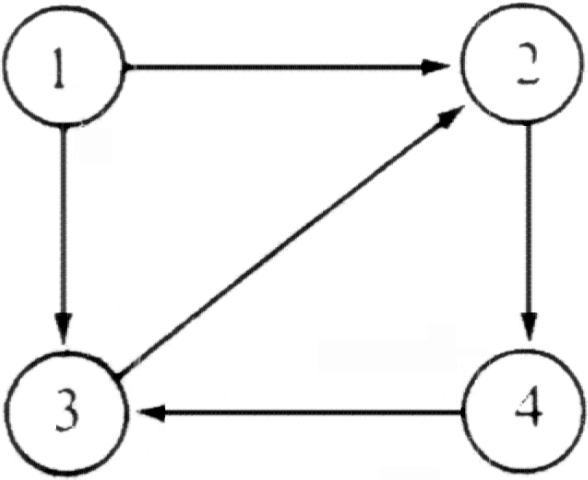
A path is simple if all vertices on the path, except possibly the first and last, are distinct. A simple cycle is a simple path of length at least one that begins and ends at the same vertex. In Fig. 6.1, the path 3, 2, 4, 3 is a cycle of length three.
In many applications it is useful to attach information to the vertices and arcs of a digraph. For this purpose we can use a labeled digraph, a digraph in which each arc and/or each vertex can have an associated label. A label can be a name, a cost, or a value of any given data type.
Example 6.2. Figure 6.2 shows a labeled digraph in which each arc is labeled by a letter that causes a transition from one vertex to another. This labeled digraph has the interesting property that the arc labels on every cycle from vertex 1 back to vertex 1 spell out a string of a's and b's in which both the number of a's and b's is even.
In a labeled digraph a vertex can have both a name and a label. Quite frequently, we shall use the vertex label as the name of the vertex. Thus, the numbers in Fig. 6.2 could be interpreted as vertex names or vertex labels.
Several data structures can be used to represent a directed graph. The appropriate choice of data structure depends on the operations that will be applied to the vertices and arcs of the digraph. One common representation for a digraph G = (V,E) is the adjacency matrix. Suppose V = {1, 2 , . . . , n}. The adjacency matrix for G is an n x n matrix A of booleans, where A[i, j] is true if and only if there is an arc from vertex i to j. Often, we shall exhibit adjacency matrices with 1 for true and 0 for false; adjacency matrices may even be implemented that way. In the adjacency matrix representation the time required to access an element of an adjacency matrix is independent of the size of V and E. Thus the adjacency matrix

Fig. 6.2. Transition digraph.
representation is useful in those graph algorithms in which we frequently need to know whether a given arc is present.Closely related is the labeled adjacency matrix representation of a digraph, where A[i, j] is the label on the arc going from vertex i to vertex j. If there is no arc from i to j, then a value that cannot be a legitimate label must be used as the entry for A[i, j].
Example 6.3. Figure 6.3 shows the labeled adjacency matrix for the digraph of Fig. 6.2. Here, the label type is char, and a blank represents the absence of an arc.
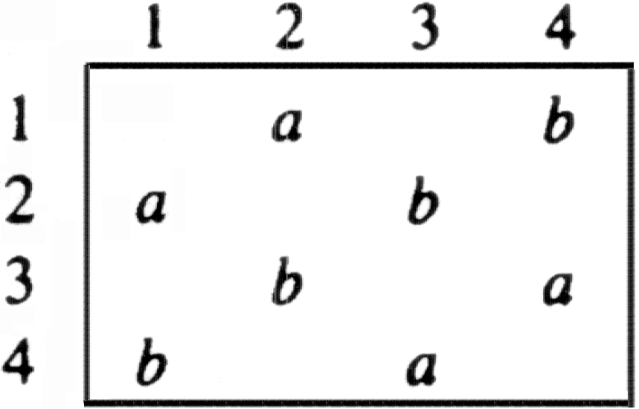
Fig. 6.3. Labeled adjacency matrix for digraph of Fig. 6.2.
The main disadvantage of using an adjacency matrix to represent a digraph is that the matrix requires W(n2) storage even if the digraph has many fewer than n2 arcs. Simply to read in or examine the matrix would require O(n2) time, which would preclude O(n) algorithms for manipulating digraphs with O(n) arcs.
To avoid this disadvantage we can use another common representation for a digraph G = (V,E) called the adjacency list representation. The adjacency list for a vertex i is a list, in some order, of all vertices adjacent to i. We can represent G by an array HEAD, where HEAD[i] is a pointer to the adjacency list for vertex i. The adjacency list representation of a digraph requires storage proportional to sum of the number of vertices plus the number of arcs; it is often used when the number of arcs is much less than n2. However, a potential disadvantage of the adjacency list representation is that it may take O(n) time to determine whether there is an arc from vertex i to vertex j, since there can be O(n) vertices on the adjacency list for vertex i.
Example 6.4. Figure 6.4 shows an adjacency list representation for the digraph of Fig. 6.1, where singly linked lists are used. If arcs had labels, these could be included in the cells of the linked list.
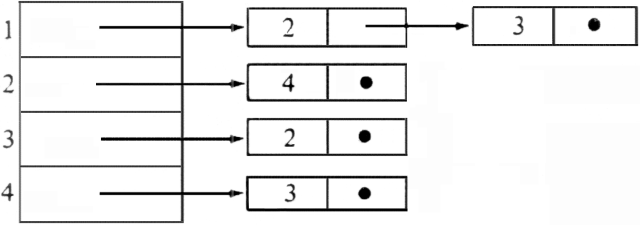
Fig. 6.4. Adjacency list representation for digraph of Fig. 6.1.
If we did insertions and deletions from the adjacency lists, we might prefer to have the HEAD array point to header cells that did not contain adjacent vertices.† Alternatively, if the graph were expected to remain fixed, with no (or very few) changes to be made to the adjacency lists, we might prefer HEAD[i] to be a cursor to an array ADJ, where ADJ[HEAD[i]], ADJ[HEAD[i]+ 1] , . . . , and so on, contained the vertices adjacent to vertex i, up to that point in ADJ where we first encounter a 0, which marks the end of the list of adjacent vertices for i. For example, Fig. 6.1 could be represented as in Fig. 6.5.
We could define an ADT corresponding to the directed graph formally and study implementations of its operations. We shall not pursue this direction extensively, because there is little of a surprising nature, and the principal data structures for graphs have already been covered. The most common operations on directed graphs include operations to read the label of a vertex or arc, to insert or delete vertices and arcs, and to navigate by following arcs

Fig. 6.5. Another adjacency list representation of Fig. 6.1.
from tail to head.The latter operations require a little thought. Most frequently, we shall encounter in informal programs statements like
for each vertex w adjacent to vertex v do (6.1)
{ some action on w }
To implement such a step, we need the notion of an index type for the set of vertices adjacent to some one vertex v. For example, if adjacency lists are used to represent the graph, then an index is really a position on the adjacency list for v. If an adjacency matrix is used, an index is an integer representing an adjacent vertex. We need the following three operations on directed graphs.
Example 6.5. If the adjacency matrix representation is chosen, VERTEX(v, i) returns i. FIRST(v) and NEXT(v, i) can be written as in Fig. 6.6 to operate on an externally defined n x n boolean matrix A. We assume A is declared
array [1..n, 1..n] of booleanand that 0 is used for L. We can then implement the statement (6.1) as in Fig. 6.7. Note that FIRST(v) can also be implemented as NEXT(v, 0).
function FIRST ( v: integer ): integer;
var
i: integer;
begin
for i := 1 to n do
if A[v, i] then
return (i);
return (0) { if we reach here, v has no adjacent vertex }
end; { FIRST }
function NEXT ( v: integer; i: integer ): integer;
var
j: integer;
begin
for j := i + 1 to n do
if A[v, j] then
return (j);
return (0)
end; { NEXT }
Fig. 6.6. Operations to scan adjacent vertices.
i := FIRST(v);
while i <> L do begin
w := VERTEX(v, i);
{ some action on w }
i := NEXT(v, i)
end
Fig. 6.7. Iteration over vertices adjacent to v.
In this section we consider a common path-finding problem on directed graphs. We are given a directed graph G = (V, E) in which each arc has a nonnegative label, and one vertex is specified as the source. Our problem is to determine the cost of the shortest path from the source to every other vertex in V, where the length of a path is just the sum of the costs of the arcs on the path. This problem is often called the single-source shortest paths problem.† Note that we shall talk of paths as having "length" even if costs represent something different, like time.
We might think of G as a map of airline flights, in which each vertex represents a city and each arc v ?/FONT> w an airline route from city v to city w. The label on arc v ?/FONT> w is the time to fly from v to w.‡ Solving the single-source shortest paths problem for this directed graph would determine the minimum travel time from a given city to every other city on the map.
To solve this problem we shall use a "greedy" technique, often known as Dijkstra's algorithm. The algorithm works by maintaining a set S of vertices whose shortest distance from the source is already known. Initially, S contains only the source vertex. At each step, we add to S a remaining vertex v whose distance from the source is as short as possible. Assuming all arcs have nonnegative costs, we can always find a shortest path from the source to v that passes only through vertices in S. Call such a path special. At each step of the algorithm, we use an array D to record the length of the shortest special path to each vertex. Once S includes all vertices, all paths are "special," so D will hold the shortest distance from the source to each vertex.
The algorithm itself is given in Fig. 6.8. It assumes that we are given a directed graph G = (V, E) where V = {1, 2, . . . , n} and vertex 1 is the source. C is a two-dimensional array of costs, where C[i, j] is the cost of going from vertex i to vertex j on arc i ?/FONT> j. If there is no arc i ?/FONT> j, then we assume C[i, j] is ?/FONT>, some value much larger than any actual cost. At each step D [i] contains the length of the current shortest special path to vertex i.
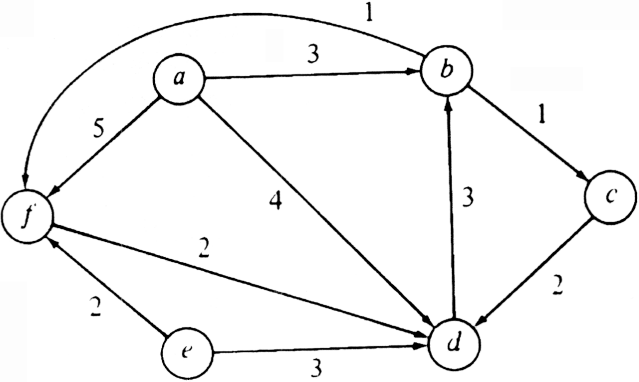
Example 6.6. Let us apply Dijkstra to the directed graph of Fig. 6.9. Initially, S = {1}, D[2] = 10, D[3] = ?/FONT>, D[4] = 30 and D[5] = 100. In the first iteration of the for-loop of lines (4)-(8), w = 2 is selected as the vertex with the minimum D value. Then we set D[3] = min(?/FONT>, 10+50)= 60. D(4) and D(5) do not change, because reaching them from 1 directly is shorter than going through vertex 2. The sequence of D-values after each iteration of the for-loop is shown in Fig. 6.10.
If we wish to reconstruct the shortest path from the
source to each vertex,
then we can maintain another array P of vertices, such that P [v] contains the
vertex immediately before vertex v in the shortest path. Initialize P[v] to 1
for all v ?/FONT> 1. The P-array can be updated right after
line (8) of Dijkstra. If
D[w]+C[w,v]<D[v] at line (8), then we set
P[v]:= w. Upon termination
Fig. 6.8. Dijkstra's algorithm.
Fig. 6.9. Digraph with labeled arcs.
procedure Dijkstra;
{ Dijkstra computes the cost of the shortest paths
from vertex 1 to every vertex of a directed graph }
begin
(1) S := {1};
(2) for i := 2 to n do
(3) D[i] := C[1, i]; { initialize D }
(4) for i := 1 to n-1 do begin
(5) choose a vertex w in V-S such that
D[w] is a minimum;
(6) add w to S;
(7) for each vertex v in V-S do
(8) D[v] := min(D[v], D[w] +
C[w, v])
end
end; { Dijkstra }

Example 6.7. For the digraph in Example 6.6 the P-array would have the values P[2] = 1, P[3] = 4, P[4] = 1, and P[5] = 3. To find the shortest path from vertex 1 to vertex 5, for example, we would trace the predecessors in reverse order beginning at vertex 5. From the P-array we determine 3 is the predecessor of 5, 4 the predecessor of 3, and 1 the predecessor of 4. Thus the shortest path from vertex 1 to vertex 5 is 1, 4, 3, 5.

Fig. 6.10. Computation of Dijkstra on digraph of Fig. 6.9.
Dijkstra's algorithm is an example where "greed" pays off, in the sense that what appears locally as the best thing to do turns out to be the best over all. In this case, the locally "best" thing to do is to find the distance to the vertex w that is outside S but has the shortest special path. To see why in this case there cannot be a shorter nonspecial path from the source to w, observe Fig. 6.11. There we show a hypothetical shorter path to w that first leaves S to go to vertex x, then (perhaps) wanders into and out of S several times before ultimately arriving at w.
But if this path is shorter than the shortest special path to w, then the initial segment of the path from the source to x is a special path to x shorter than the shortest special path to w. (Notice how important the fact that costs are nonnegative is here; without it our argument wouldn't work, and in fact Dijkstra's algorithm would not work correctly.) In that case, when we selected w at line (5) of Fig. 6.8, we should have selected x instead, because D [x] was less than D [w].
To complete a proof that Fig. 6.8 works, we should verify that at all times D [v] is truly the shortest distance of a special path to vertex v. The crux of this argument is in observing that when we add a new vertex w to S at line (6), lines (7) and (8) adjust D to take account of the possibility that there is now a shorter special path to v going through w. If that path goes through the old S to w and then immediately to v, its cost, D [w]+C [w, v], will be compared with D [v] at line (8), and D [v] will be reduced if the new special path is shorter. The only other possibility for a shorter special path is shown in Fig. 6.12, where the path travels to w, then back into the old S, to some member x of the old S, then to v.
But there really cannot be such a path. Since x was placed in S before w, the shortest of all paths from the source to x runs through the old S alone. Therefore, the path to x through w shown in Fig. 6.12 is no shorter than the path directly to x through S. As a result, the length of the path in Fig. 6.12 from the source to w, x, and v is no less from the old value of D [v], since D [v] was no greater than the length of the shortest path to x through S and then directly to v. Thus D [v] cannot be reduced at line (8) by a path through w and x as in Fig. 6.12, and we need not consider the length of such paths.
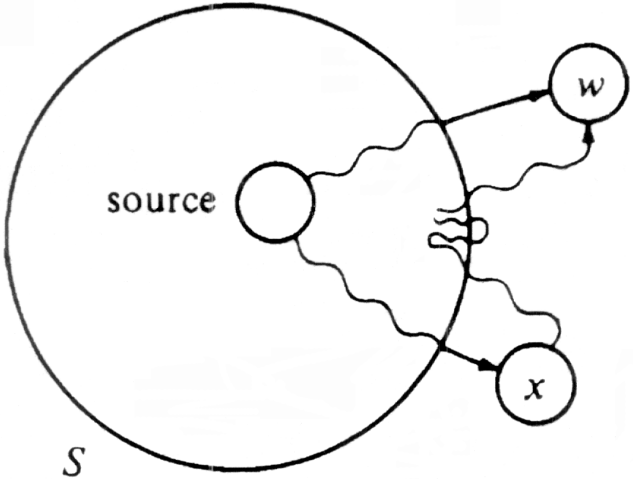
Fig. 6.11. Hypothetical shorter path to w.

Fig. 6.12. Impossible shortest special path.
Suppose Fig. 6.8 operates on a digraph with n vertices and e edges. If we use an adjacency matrix to represent the digraph, then the loop of lines (7) and (8) takes O(n) time, and it is executed n-1 times for a total time of O(n2). The rest of the algorithm is easily seen to require no more time than this.
If e is much less than n2, we might do better by using an adjacency list representation of the digraph and using a priority queue implemented as a partially ordered tree to organize the vertices in V-S. The loop of lines (7) and (8) can then be implemented by going down the adjacency list for w and updating the distances in the priority queue. A total of e updates will be made, each at a cost of O(logn) time, so the total time spent in lines (7) and (8) is now O(elogn), rather than O(n2).
Lines (1)-(3) clearly take O(n) time, as do lines (4) and (6). Using the priority queue to represent V-S, lines (5)-(6) implement exactly the DELETEMIN operation, and each of the n-1 iterations of these lines requires O(logn) time.
As a result, the total time spent on this version of Dijkstra's algorithm is bounded by O(elogn). This running time is considerably better than O(n2) if e is very small compared with n2.
Suppose we have a labeled digraph that gives the flying time on certain routes connecting cities, and we wish to construct a table that gives the shortest time required to fly from any one city to any other. We now have an instance of the all-pairs shortest paths (APSP) problem. To state the problem precisely, we are given a directed graph G = (V, E) in which each arc v ?/FONT> w has a non-negative cost C[v, w]. The APSP problem is to find for each ordered pair of vertices (v, w) the smallest length of any path from v to w.
We could solve this problem using Dijkstra's algorithm with each vertex in turn as the source. A more direct way of solving the problem is to use the following algorithm due to R. W. Floyd. For convenience, let us again assume the vertices in V are numbered 1, 2 , . . . , n. Floyd's algorithm uses an n x n matrix A in which to compute the lengths of the shortest paths. We initially set A[i, j] = C[i, j] for all i ?/FONT> j. If there is no arc from i to j, we assume C[i, j] = ?/FONT>. Each diagonal element is set to 0.
We then make n iterations over the A matrix. After the kth iteration, A[i, j] will have for its value the smallest length of any path from vertex i to vertex j that does not pass through a vertex numbered higher than k. That is to say, i and j, the end vertices on the path, may be any vertex, but any intermediate vertex on the path must be less than or equal to k.
In the kth iteration we use the following formula to compute A.

To compute Ak[i, j] we compare Ak- 1[i, j], the cost of going from i to j without going through k or any higher-numbered vertex, with Ak-1[i, k] + Ak- 1[k, j], the cost of going first from i to k and then from k to j, without passing through a vertex numbered higher than k. If passing through vertex k produces a cheaper path than what we had for Ak- 1[i, j], then we choose that cheaper cost for Ak[i, j].

Fig. 6.13. Including k among the vertices to go from i to j.
Example 6.8. Consider the weighted digraph shown in Fig. 6.14. The values of the A matrix initially and after the three iterations are shown in Fig. 6.15.

Fig. 6.14. Weighted digraph.
Since Ak[i, k] = Ak-1[i, k] and Ak[k, j] = Ak-1[k, j], no entry with either subscript equal to k changes during the kth iteration. Therefore, we can perform the computation with only one copy of the A matrix. A program to perform this computation on n x n matrices is shown in Fig. 6.16.
The running time of this program is clearly O(n3), since the program is basically nothing more than a triply nested for-loop. To verify that this program works, it is easy to prove by induction on k that after k passes through the triple for-loop, A[i, j] holds the length of the shortest path from vertex i to vertex j that does not pass through a vertex numbered higher than k.

Fig. 6.15. Values of successive A matrices.
procedure Floyd ( var A: array[1..n, 1..n]
of real;
C: array[1..n, 1..n] of real );
{ Floyd computes shortest path matrix A given arc cost matrix C }
var
i, j, k: integer;
begin
for i := 1 to n do
for j := 1 to n do
A[i, j] := C[i, j];
for i:= 1 to n do
A[i, i] := 0;
for k:= 1 to n do
for i := 1 to n do
for j:= 1 to n do
if A[i, k] + A[k, j] < A
[i, j] then
A[i, j] := A[i, k] + A[k,
j]
end; { Floyd }
Fig. 6.16. Floyd's algorithm.
Since the adjacency-matrix version of Dijkstra finds shortest paths from one vertex in O(n2) time, it, like Floyd's algorithm, can find all shortest paths in O(n3) time. The compiler, machine, and implementation details will determine the constants of proportionality. Experimentation and measurement are the easiest way to ascertain the best algorithm for the application at hand.
If e, the number of edges, is very much less than n2, then despite the relatively low constant factor in the O(n3) running time of Floyd, we would expect the adjacency list version of Dijkstra, taking O(ne logn) time to solve the APSP, to be superior, at least for large sparse graphs.
In many situations we may want to print out the cheapest path from one vertex to another. One way to accomplish this is to use another matrix P, where P[i, j] holds that vertex k that led Floyd to find the smallest value of A[i, j]. If P[i, j]=0, then the shortest path from i to j is direct, following the arc from i to j. The modified version of Floyd in Fig. 6.17 stores the appropriate intermediate vertices into P.
procedure shortest ( var A: array[1..n, 1..n]
of real;
C: array[1..n, 1..n] of real; P:
array[1..n, 1..n] of integer );
{ shortest takes an n X n matrix C of arc costs and produces an
n X n matrix A of lengths of shortest paths and an n X n
matrix
P giving a point in the "middle" of each shortest path }
var
i, j, k: integer;
begin
for i:= 1 to n do
for j := 1 to n do begin
A[i, j] := C[i, j];
P[i, j] := 0
end;
for i:= 1 to n do
A[i, i] := 0;
for k := 1 to n do
for i:= 1 to n do
for j:= 1 to n do
if A[i, k] + A[k, j] <
A[i, j] then begin
A[i, j] := A[i, k] + A[k,
j];
P[i, j] := k
end
end; { shortest }
Fig. 6.17. Shortest paths program.
To print out the intermediate vertices on the shortest path from vertex i to vertex j, we invoke the procedure path(i, j) where path is given in Fig. 6.18. While on an arbitrary matrix P, path could loop forever, if P comes from shortest, we could not, say, have k on the shortest path from i to j and also have j on the shortest path from i to k. Note how our assumption of nonnegative weights is again crucial.
procedure path ( i, j: integer );
var
k: integer;
begin
k := P[i, j];
if k = 0 then
return;
path(i, k);
writeln(k);
path(k, j)
end; { path }
Fig. 6.18. Procedure to print shortest path.
Example 6.9. Figure 6.19 shows the final P matrix for the digraph of Fig. 6.14.
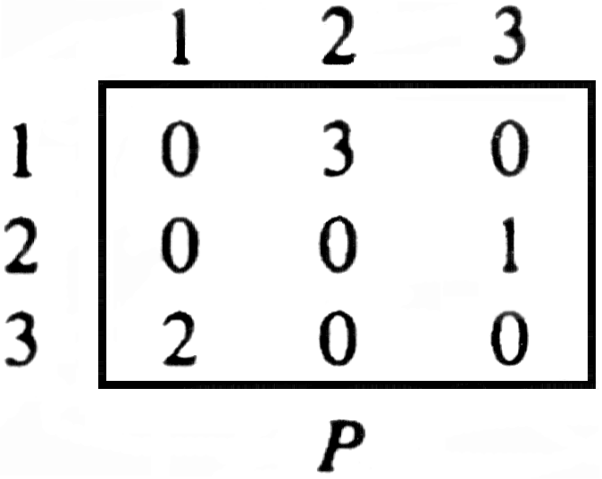
Fig. 6.19. P matrix for digraph of Fig. 6.14.
In some problems we may be interested in determining only whether there exists a path of length one or more from vertex i to vertex j. Floyd's algorithm can be specialized readily to this problem; the resulting algorithm, which predates Floyd's, is called Warshall's algorithm.
Suppose our cost matrix C is just the adjacency matrix for the given digraph. That is, C[i, j] = 1 if there is an arc from i to j, and 0 otherwise. We wish to compute the matrix A such that A[i, j] = 1 if there is a path of length one or more from i to j, and 0 otherwise. A is often called the transitive closure of the adjacency matrix.
Example 6.10. Figure 6.20 shows the transitive closure for the adjacency matrix of the digraph of Fig. 6.14.
The transitive closure can be computed using a procedure similar to Floyd by applying the following formula in the kth pass over the boolean A matrix.
Ak[i, j] = Ak-1[i, j] or (Ak-1[i, k] and Ak- 1[k, j])
This formula states that there is a path from i to j not passing through a

Fig. 6.20. Transitive closure.
vertex numbered higher than k ifAs before Ak[i, k] = Ak-1[i, k] and Ak[k, j] = Ak-1[k, j] so we can perform the computation with only one copy of the A matrix. The resulting Pascal program, named Warshall after its discoverer, is shown in Fig. 6.21.
procedure Warshall ( var A: array[1..n, 1..n
] of boolean;
C: array[1..n, 1..n] of boolean );
{ Warshall makes A the transitive closure of C }
var
i, j, k: integer;
begin
for i := 1 to n do
for j := 1 to n do
A[i, j] := C[i, j];
for k := 1 to n do
for i := 1 to n do
for j := 1 to n do
if A[i, j ] = false then
A[i, j] := A[i, k] and
A[k, j]
end; { Warshall }
Fig. 6.21. Warshall's algorithm for transitive closure.
Suppose we wish to determine the most central vertex in a digraph. This problem can be readily solved using Floyd's algorithm. First, let us make more precise the term "most central vertex." Let v be a vertex in a digraph G = (V, E). The eccentricity of v is
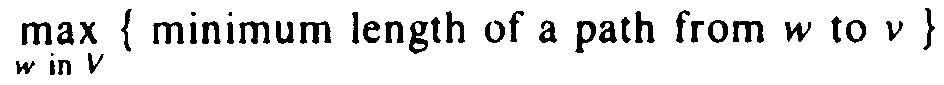
Example 6.11. Consider the weighted digraph shown in Fig. 6.22.
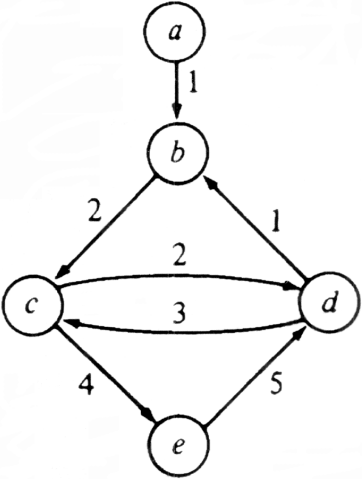
Fig. 6.22. Weighted digraph.
The eccentricities of the vertices are
vertex eccentricity
a ?/FONT>
b 6
c 8
d 5
e 7
Thus the center is vertex d.
Finding the center of a digraph G is easy. Suppose C is the cost matrix for G.
This running time of this process is dominated by the first step, which takes O(n3) time. Step (2) takes O(n2) time and step (3) O(n) time.
Example 6.12. The APSP cost matrix for Fig. 6.22 is shown in Fig. 6.23. The maximum value in each column is shown below.

Fig. 6.23. APSP cost matrix.
To solve many problems dealing with directed graphs efficiently we need to visit the vertices and arcs of a directed graph in a systematic fashion. Depth-first search, a generalization of the preorder traversal of a tree, is one important technique for doing so. Depth-first search can serve as a skeleton around which many other efficient graph algorithms can be built. The last two sections of this chapter contain several algorithms that use depth-first search as a foundation.
Suppose we have a directed graph G in which all vertices are initially marked unvisited. Depth-first search works by selecting one vertex v of G as a start vertex; v is marked visited. Then each unvisited vertex adjacent to v is searched in turn, using depth-first search recursively. Once all vertices that can be reached from v have been visited, the search of v is complete. If some vertices remain unvisited, we select an unvisited vertex as a new start vertex. We repeat this process until all vertices of G have been visited.
This technique is called depth-first search because it continues searching in the forward (deeper) direction as long as possible. For example, suppose x is the most recently visited vertex. Depth-first search selects some unexplored arc x ?/FONT> y emanating from x. If y has been visited, the procedure looks for another unexplored arc emanating from x. If y has not been visited, then the procedure marks y visited and initiates a new search at y. After completing the search through all paths beginning at y, the search returns to x, the vertex from which y was first visited. The process of selecting unexplored arcs emanating from x is then continued until all arcs from x have been explored.
An adjacency list L[v] can be used to represent the vertices adjacent to vertex v, and an array mark, whose elements are chosen from (visited, unvisited), can be used to determine whether a vertex has been previously visited. The recursive procedure dfs is outlined in Fig. 6.24. To use it on an n-vertex graph, we initialize mark to unvisited and then commence a depth-first search from each vertex that is still unvisited when its turn comes, by
for v := 1 to n do
mark[v] := unvisited;
for v := 1 to n do
if mark[v] = unvisited then
dfs( v )
Note that Fig. 6.24 is a template to which we shall attach other actions later,
as we apply depth-first search. The code in Fig. 6.24 doesn't do anything but
set the mark array.
All the calls to dfs in the depth-first search of a graph with e arcs and n ?/FONT> e vertices take O(e) time. To see why, observe that on no vertex is dfs called more than once, because as soon as we call dfs(v) we set mark[v] to visited at line (1), and we never call dfs on a vertex that previously had its mark set to visited. Thus, the total time spent at lines (2)-(3) going down the adjacency lists is proportional to the sum of the lengths of those lists, that is, O(e). Thus, assuming n?/FONT>e, the total time spent on the depth- first search of an entire graph is O(e), which is, to within a constant factor, the time needed merely to "look at" each arc.
procedure dfs ( v: vertex );
var
w: vertex;
begin
(1) mark[v]: = visited;
(2) for each vertex w on L[v] do
(3) if mark[w] = unvisited then
(4) dfs(w)
end; { dfs }
Fig. 6.24. Depth-first search.
Example 6.13. Assume the procedure dfs(v) is applied to the directed graph of Fig. 6.25 with v = A. The algorithm marks A visited and selects vertex B from the adjacency list of vertex A. Since B is unvisited, the search continues by calling dfs(B). The algorithm now marks B visited and selects the first vertex from the adjacency list for vertex B. Depending on the order of the vertices on the adjacency list of B the search will go to C or D next.
Assuming that C appears ahead of D, dfs(C) is invoked. Vertex A is on the adjacency list of C. However, A is already visited at this point so the
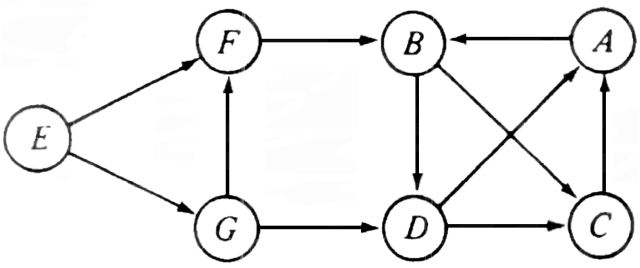
Fig. 6.25. Directed graph.
search remains at C. Since all vertices on the adjacency list at C have now been exhausted, the search returns to B, from which the search proceeds to D. Vertices A and C on the adjacency list of D were already visited, so the search returns to B and then to A.At this point the original call of dfs(A) is complete. However, the digraph has not been entirely searched; vertices E, F and G are still unvisited. To complete the search, we can call dfs(E).
During a depth-first traversal of a directed graph, certain arcs, when traversed, lead to unvisited vertices. The arcs leading to new vertices are called tree arcs and they form a depth-first spanning forest for the given digraph. The solid arcs in Fig. 6.26 form a depth-first spanning forest for the digraph of Fig. 6.25. Note that the tree arcs must indeed form a forest, since a vertex cannot be unvisited when two different arcs to it are traversed.
In addition to the tree arcs, there are three other types of arcs defined by a depth-first search of a directed graph. These are called back arcs, forward arcs, and cross arcs. An arc such as C ?/FONT> A is called a back arc, since it goes from a vertex to one of its ancestors in the spanning forest. Note that an arc from a vertex to itself is a back arc. A nontree arc that goes from a vertex to a proper descendant is called a forward arc. There are no forward arcs in Fig. 6.26.
Arcs such as D ?/FONT> C or G ?/FONT> D, which go from a vertex to another vertex that is neither an ancestor nor a descendant, are called cross arcs. Observe that all cross arcs in Fig. 6.26 go from right to left, on the assumption that we add children to the tree in the order they were visited, from left to right, and that we add new trees to the forest from left to right. This pattern is not accidental. Had the arc G ?/FONT> D been the arc D ?/FONT> G, then G would have been unvisited when the search at D was in progress, and thus on encountering arc D ?/FONT> G, vertex G would have been made a descendant of D, and D ?/FONT> G would have become a tree arc.
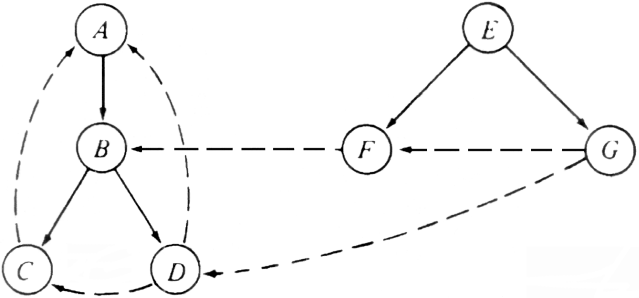
Fig. 6.26. Depth-first spanning forest for Fig. 6.25.
How do we distinguish among the four types of arcs? Clearly tree arcs are special since they lead to unvisited vertices during the depth-first search. Suppose we number the vertices of a directed graph in the order in which we first mark them visited during a depth-first search. That is, we may assign to an array
dfnumber [v] := count; count : = count + 1;after line (1) of Fig. 6.24. Let us call this the depth-first numbering of a directed graph; notice how depth-first numbering generalizes the preorder numbering introduced in Section 3.1.
All descendants of a vertex v are assigned depth-first search numbers greater than or equal to the number assigned v. In fact, w is a descendant of v if and only if dfnumber(v) ?/FONT> dfnumber(w) ?/FONT> dfnumber(v) + number of descendants of v. Thus, forward arcs go from low-numbered to high-numbered vertices and back arcs go from high-numbered to low-numbered vertices.
All cross arcs go from high-numbered vertices to low-numbered vertices. To see this, suppose that x ?/FONT> y is an arc and dfnumber(x) ?/FONT> dfnumber(y). Thus x is visited before y. Every vertex visited between the time dfs(x) is first invoked and the time dfs(x) is complete becomes a descendant of x in the depth-first spanning forest. If y is unvisited at the time arc x ?/FONT> y is explored, x ?/FONT> y becomes a tree arc. Otherwise, x ?/FONT> y is a forward arc. Thus there can be no cross arc x ?/FONT> y with dfnumber (x) ?/FONT> dfnumber (y).
In the next two sections we shall show how depth- first search can be used in solving various graph problems.
A directed acyclic graph, or dag for short, is a directed graph with no cycles. Measured in terms of the relationships they can represent, dags are more general than trees but less general than arbitrary directed graphs. Figure 6.27 gives an example of a tree, a dag, and a directed graph with a cycle.

Fig. 6.27. Three directed graphs.
Among other things, dags are useful in representing the syntactic structure of arithmetic expressions with common subexpressions. For example, Fig. 6.28 shows a dag for the expression
((a+b)*c + ((a+b)+e) * (e+f)) * ((a+b)*c)
The terms a+b and (a+b)*c are shared common subexpressions that are represented by vertices with more than one incoming arc.
Dags are also useful in representing partial orders. A partial order R on a set S is a binary relation such that
Two natural examples of partial orders are the "less than" (<) relation on integers, and the relation of proper containment (?/FONT>) on sets.
Example 6.14. Let S = {1, 2, 3} and let P(S) be the power set of S, that is, the set of all subsets of S. P(S) = {Ø, {1}, {2}, {3}, {1,2}, {1,3}, {2,3}, {1,2,3}}. ?/FONT> is a partial order on P(S). Certainly, A ?/FONT> A is false for any set A (irreflexivity), and if A ?/FONT> B and B ?/FONT> C, then A ?/FONT> C (transitivity).
Dags can be used to portray partial orders graphically. To begin, we can view a relation R as a set of pairs (arcs) such that (a, b) is in the set if and only if a R b is true. If R is a partial order on a set S, then the directed graph G = (S ,R) is a dag. Conversely, suppose G = (S ,R) is a dag and R+ is the relation defined by a R+ b if and only if there is a path of length one or
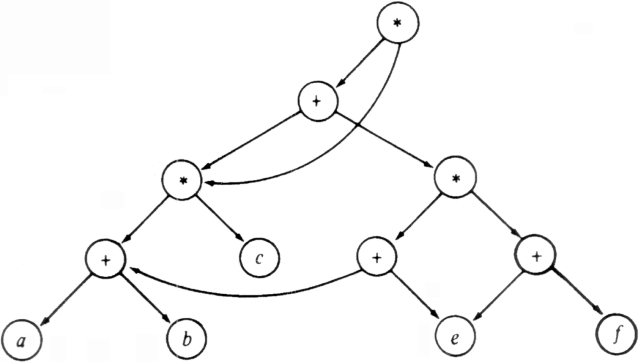
Fig. 6.28. Dag for arithmetic expression.
more from a to b. (R+ is the transitive closure of the relation R.) Then, R+ is a partial order on S.
Example 6.15. Figure 6.29 shows a dag (P(S), R), where S = {1, 2 ,3}. The relation R+ is proper containment on the power set P(S).

Fig. 6.29. Dag of proper containments.
Suppose we are given a directed graph G = (V, E), and we wish to determine whether G is acyclic, that is, whether G has no cycles. Depth-first search can be used to answer this question. If a back arc is encountered during a depth-first search of G, then clearly the graph has a cycle. Conversely, if a directed graph has a cycle, then a back arc will always be encountered in any depth-first search of the graph.
To see this fact, suppose G is cyclic. If we do a depth-first search of G, there will be one vertex v having the lowest depth-first search number of any vertex on a cycle. Consider an arc u ?/FONT> v on some cycle containing v. Since u is on the cycle, u must be a descendant of v in the depth-first spanning forest. Thus, u ?/FONT> v cannot be a cross arc. Since the depth- first number of u is greater than the depth-first number of v, u ?/FONT> v cannot be a tree arc or a forward arc. Thus, u ?/FONT> v must be a back arc, as illustrated in Fig. 6.30.
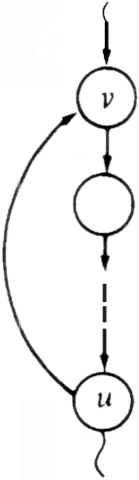
Fig. 6.30. Every cycle contains a back arc.
A large project is often divided into a collection of smaller tasks, some of which have to be performed in certain specified orders so that we may complete the entire project. For example, a university curriculum may have courses that require other courses as prerequisites. Dags can be used to model such situations naturally. For example, we could have an arc from course C to course D if C is a prerequisite for D.
Example 6.16. Figure 6.31 shows a dag giving the prerequisite structure on five courses. Course C3, for example, requires courses C1 and C2 as prerequisites.

Fig. 6.31. Dag of prerequisites.
Topological sort is a process of assigning a linear ordering to the vertices of a dag so that if there is an arc from vertex i to vertex j, then i appears before j in the linear ordering. For example, C1, C2, C3, C4, C5 is a topological sort of the dag in Fig. 6.31. Taking the courses in this sequence would satisfy the prerequisite structure given in Fig. 6.31.
Topological sort can be easily accomplished by
adding a print statement
after line (4) to the depth-first search procedure in Fig. 6.24:
procedure topsort ( v: vertex );
{ print vertices accessible from v in reverse topological order }
var
w: vertex;
begin
mark[v] := visited;
for each vertex w on L[v] do
if mark[w] = unvisited then
topsort(w) ;
writeln(v)
end; { topsort }
When topsort finishes searching all vertices adjacent to a given vertex x, it prints x. The effect of calling topsort (v) is to print in a reverse topological order all vertices of a dag accessible from v by a path in the dag.
This technique works because there are no back arcs in a dag. Consider what happens when depth-first search leaves a vertex x for the last time. The only arcs emanating from v are tree, forward, and cross arcs. But all these arcs are directed towards vertices that have already been completely visited by the search and therefore precede x in the order being constructed.
A strongly connected component of a directed graph is a maximal set of vertices in which there is a path from any one vertex in the set to any other vertex in the set. Depth-first search can be used to determine strongly connected components of a directed graph efficiently.
Let G = (V, E) be a directed graph. We can partition V into equivalence classes Vi, 1?/FONT>i?/FONT>r, such that vertices v and w are equivalent if and only if there is a path from v to w and a path from w to v. Let Ei, 1?/FONT>i?/FONT>r, be the set of arcs with head and tail in Vi. The graphs Gi = (Vi, Ei) are called the strongly connected components (or just strong components) of G. A directed graph with only one strong component is said to be strongly connected.Example 6.17. Figure 6.32 illustrates a directed graph with the two strong components shown in Fig. 6.33.
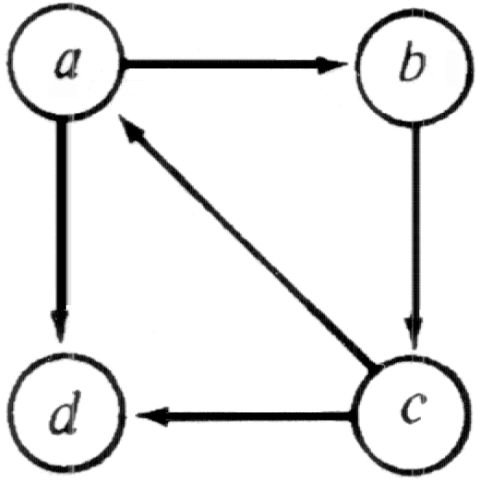
Fig. 6.32. Directed graph.
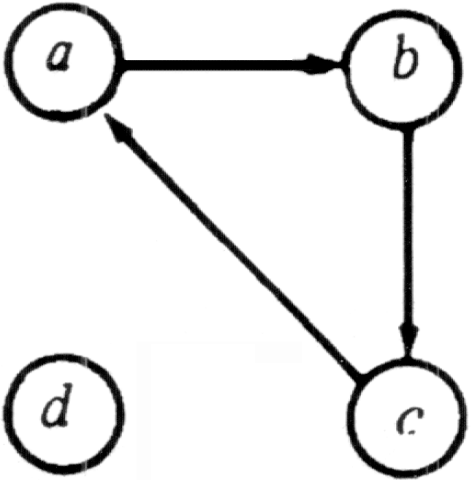
Fig. 6.33. The strong components of the digraph of Fig. 6.32.
Note that every vertex of a directed graph G is in some strong component, but that certain arcs may not be in any component. Such arcs, called cross-component arcs, go from a vertex in one component to a vertex in another. We can represent the interconnections among the components by constructing a reduced graph for G. The vertices of the reduced graph are the strongly connected components of G. There is an arc from vertex C to a different vertex C' of the reduced graph if there is an arc in G from some vertex in the component C to some vertex in component C'. The reduced graph is always a dag, because if there were a cycle, then all the components in the cycle would really be one strong component, meaning that we didn't compute strong components properly. Figure 6.34 shows the reduced graph for the digraph in Figure 6.32.
We shall now present an algorithm to find the
strongly connected

Fig. 6.34. Reduced graph.
components of a given directed graph G.Example 6.18. Let us apply this algorithm to the directed graph of Fig. 6.32, starting at a and progressing first to b. After step (1) we number the vertices as shown in Fig. 6.35. Reversing the direction of the arcs we obtain the directed graph Gr in Fig. 6.36.
Performing the depth-first search on Gr we obtain the depth-first spanning forest shown in Fig. 6.37. We begin with a as a root, because a has the highest number. From a we can only reach c and then b. The next tree has root d, since that is the highest numbered (and only) remaining vertex. Each tree in this forest forms a strongly connected component of the original directed graph.
We have claimed that the vertices of a strongly connected component correspond precisely to the vertices of a tree in the spanning forest of the second depth-first search. To see why, observe that if v and w are vertices in the same strongly connected component, then there are paths in G from v to w and from w to v. Thus there are also paths from v to w and from w to v in Gr.
Suppose that in the depth-first search of
Gr, we begin a search at some
root x and reach either v or w. Since v and w are reachable from
each other,
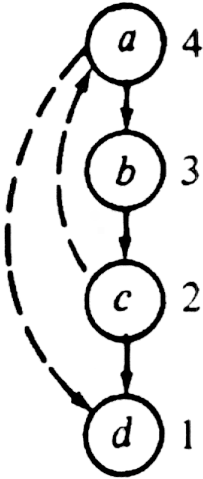
Fig. 6.35. After step 1.

Fig. 6.36. Gr.
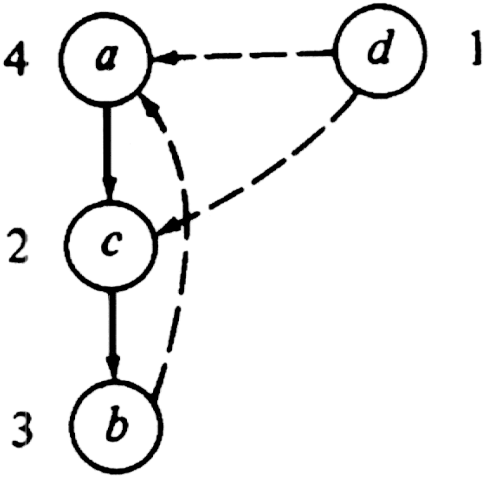
Fig. 6.37.Depth-first spanning forest for Gr.
both v and w will end up in the spanning tree with root x.Now suppose v and w are in the same spanning tree of the depth-first spanning forest of Gr. We must show that v and w are in the same strongly connected component. Let x be the root of the spanning tree containing v and w. Since v is a descendant of x, there exists a path in Gr from x to v. Thus there exists a path in G from v to x.
In the construction of the depth-first spanning forest of Gr, vertex v was still unvisited when the depth-first search at x was initiated. Thus x has a higher number than v, so in the depth-first search of G, the recursive call at v terminated before the recursive call at x did. But in the depth-first search of G, the search at v could not have started before x, since the path in G from v to x would then imply that the search at x would start and end before the search at v ended.
We conclude that in the search of G, v is visited during the search of x and hence v is a descendant of x in the first depth-first spanning forest for G. Thus there exists a path from x to v in G. Therefore x and v are in the same strongly connected component. An identical argument shows that x and w are in the same strongly connected component and hence v and w are in the same strongly connected component, as shown by the path from v to x to w and the path from w to x to v.
| 6.1 | Represent the digraph of Fig. 6.38
Fig. 6.38. Directed graph with arc costs. |
||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6.2 | Describe a mathematical model for the following scheduling problem. Given tasks T1, T2, . . . , Tn, which require times t1, t2, . . . , tn to complete, and a set of constraints, each of the form "Ti must be completed prior to the start of Tj," find the minimum time necessary to complete all tasks. | ||||||||||||||||||||||||||||||||||||||||||||
| 6.3 | Implement the operations FIRST, NEXT, and VERTEX for digraphs represented by | ||||||||||||||||||||||||||||||||||||||||||||
| 6.4 | In the digraph of Fig. 6.38 | ||||||||||||||||||||||||||||||||||||||||||||
| 6.5 | Write a complete program for Dijkstra's algorithm using a partially ordered tree as a priority queue and linked adjacency lists. | ||||||||||||||||||||||||||||||||||||||||||||
| *6.6 | Show that the program Dijkstra does not work correctly if arc costs can be negative. | ||||||||||||||||||||||||||||||||||||||||||||
| **6.7 | Show that the program Floyd still works if some of the arcs have negative cost but no cycle has negative cost. | ||||||||||||||||||||||||||||||||||||||||||||
| 6.8 | Assuming the order of the vertices is a, b , . . . , f in Fig. 6.38, construct a depth-first spanning forest; indicate the tree, forward, back and cross arcs, and indicate the depth-first numbering of the vertices. | ||||||||||||||||||||||||||||||||||||||||||||
| *6.9 | Suppose we are given a depth-first spanning forest, and we list in postorder each of the spanning trees (trees composed of spanning edges), from the leftmost to the rightmost. Show that this order is the same as the order in which the calls of dfs ended when the spanning forest was constructed. | ||||||||||||||||||||||||||||||||||||||||||||
| 6.10 | A root of a dag is a vertex r such that every vertex of the dag can be reached by a directed path from r. Write a program to determine whether a dag is rooted. | ||||||||||||||||||||||||||||||||||||||||||||
| *6.11 | Consider a dag with e arcs and with two distinguished vertices s and t. Construct an O (e) algorithm to find a maximal set of vertex disjoint paths from s to t. By maximal we mean no additional path may be added, but it does not mean that it is the largest size such set. | ||||||||||||||||||||||||||||||||||||||||||||
| 6.12 | Construct an algorithm to convert an expression tree with operators + and * into a dag by sharing common subexpressions. What is the time complexity of your algorithm? | ||||||||||||||||||||||||||||||||||||||||||||
| 6.13 | Construct an algorithm for evaluating an arithmetic expression represented as a dag. | ||||||||||||||||||||||||||||||||||||||||||||
| 6.14 | Write a program to find the longest path in a dag. What is the time complexity of your program? | ||||||||||||||||||||||||||||||||||||||||||||
| 6.15 | Find the strong components of Fig. 6.38. | ||||||||||||||||||||||||||||||||||||||||||||
| *6.16 | Prove that the reduced graph of the strong components of Section 6.7 must be a dag. | ||||||||||||||||||||||||||||||||||||||||||||
| 6.17 | Draw the first spanning forest, the reverse graph, and the second spanning forest developed by the strong components algorithm applied to the digraph of Fig. 6.38. | ||||||||||||||||||||||||||||||||||||||||||||
| 6.18 | Implement the strong components algorithm discussed in Section 6.7. | ||||||||||||||||||||||||||||||||||||||||||||
| *6.19 | Show that the strong components algorithm takes time O (e) on a directed graph of e arcs and n vertices, assuming n ?/FONT> e. | ||||||||||||||||||||||||||||||||||||||||||||
| *6.20 | Write a program that takes as input a digraph and two of its vertices. The program is to print all simple paths from one vertex to the other. What is the time complexity of your program? | ||||||||||||||||||||||||||||||||||||||||||||
| *6.21 | A transitive reduction of a directed graph G = (V, E) is any graph G' with the same vertices but with as few arcs as possible, such that the transitive closure of G' is the same as the transitive closure of G. how that if G is a dag, then the transitive reduction of G is unique. | ||||||||||||||||||||||||||||||||||||||||||||
| *6.22 | Write a program to compute the transitive reduction of a digraph. What is the time complexity of your program? | ||||||||||||||||||||||||||||||||||||||||||||
| *6.23 | G' = (V, E') is called a minimal equivalent digraph for a digraph G = (V, E) if E' is a smallest subset of E and the transitive closure of both G and G' are the same. Show that if G is acyclic, then there is only one minimal equivalent digraph, namely, the transitive reduction. | ||||||||||||||||||||||||||||||||||||||||||||
| *6.24 | Write a program to find a minimal equivalent digraph for a given digraph. What is the time complexity of your program? | ||||||||||||||||||||||||||||||||||||||||||||
| *6.25 | Write a program to find the longest simple path from a given vertex of a digraph. What is the time complexity of your program? |
Berge [1958] and Harary [1969] are two good sources for additional material on graph theory. Some books treating graph algorithms are Deo [1975], Even [1980], and Tarjan [1983].
The single-source shortest paths algorithm in Section 6.3 is from Dijkstra [1959]. The all-pairs shortest paths algorithm is from Floyd [1962] and the transitive closure algorithm is from Warshall [1962]. Johnson [1977] discusses efficient algorithms for finding shortest paths in sparse graphs. Knuth [1968] contains additional material on topological sort.
The strong components algorithm of Section 6.7 is similar to one suggested by R. Kosaraju in 1978 (unpublished), and to one published by Sharir [1981]. Tarjan [1972] contains another strong components algorithm that needs only one depth-first search traversal.
Coffman [1976] contains many examples of how digraphs can be used to model scheduling problems as in Exercise 6.2. Aho, Garey, and Ullman [1972] show that the transitive reduction of a dag is unique, and that computing the transitive reduction of a digraph is computationally equivalent to computing the transitive closure (Exercises 6.21 and 6.22). Finding the minimal equivalent digraph (Exercises 6.23 and 6.24), on the other hand, appears to be computationally much harder; this problem is NP-complete [Sahni (1974)].
† This is another manifestation of the old Pascal problem of doing insertion and deletion at arbitrary positions of singly linked lists.
† One might expect that a more natural problem is to find the shortest path from the source to one particular destination vertex. However, that problem appears just as hard in general as the single-source shortest paths problem (except that by luck we may find the path to the destination before some of the other vertices and thereby terminate the algorithm a bit earlier than if we wanted paths to all the vertices).
‡ We might assume that an undirected graph would be used here, since the label on arcs v ?/FONT> w and w ?/FONT> v would be the same. However, in fact, travel times are different in different directions because of prevailing winds. Anyway, assuming that labels on v ?/FONT> w and w ?/FONT> v are identical doesn't seem to help solve the problem.