


A file is a collection of records, each record having one or more fields The fields used to distinguish among the records are known as keys. Since the same file may be used for several different applications, the key fields for record identification will depend on the particular application. For instance, we may regard a telephone directory as a file, each record having three fields: name, address, and phone number. The key is usually the person's name. However, one may wish to locate the record corresponding to a given number, in which case the phone number field would be the key. In yet another application one may desire the phone number at a particular address, so this field too could be the key. Once we have a collection of records there are at least two ways in which to store them: sequentially or non-sequentially. For the time being let us assume we have a sequential file F and we wish to retrieve a record with a certain key value K. If F has n records with Ki the key value for record Ri, then one may carry out the retrieval by examining the key values Kn,Kn -1, ...,K1 in that order, until the correct record is located. Such a search is known as sequential search since the records are examined sequentially.
Note that the introduction of the dummy record R0 with key K0 = K simplifies the search by eliminating the need for an end of file test (i < 1) in the while loop. While this might appear to be a minor improvement, it actually reduces the running time by 50% for large n (see table 7.1). If no record in the file has key value K, then i = 0, and the above algorithm requires n + 1 comparisons. The number of key comparisons made in case of a successful search, depends on the position of the key in the file. If all keys are distinct and key Ki is being searched for, then n -i + 1 key comparisons are made. The average number of comparisons for a successful search is, therefore,
One of the better known methods for searching an ordered sequential file is called binary search. In this method, the search begins by examining the record in the middle of the file rather than the one at one of the ends as in sequential search. Let us assume that the file being searched is ordered by nondecreasing values of the key (i.e., in alphabetical order for strings) Then, based on the results of the comparison with the middle key, Km, one can draw one of the following conclusions:
(i) if K < Km then if the record being searched for is in the file, it must be in the lower numbered half of the file;
(ii) if K = Km then the middle record is the one being searched for;
(iii) if K > Km then if the record being searched for is in the file, it must be in the higher numbered half of the file.
Consequently, after each comparison either the search terminates successfully or the size of the file remaining to be searched is about one half of the original size (note that in the case of sequential search, after each comparison the size of the file remaining to be searched decreases by only 1). So after k key comparisons the file remaining to be examined is of size at most
In the binary search method described above, it is always the key in the middle of the subfile currently being examined that is used for comparison. This splitting process can be described by drawing a binary decision tree in which the value of a node is the index of the key being tested. Suppose there are 31 records, then the first key tested is K16 since
A path from the root to any node in the tree represents a sequence of comparisons made by BINSRCH to either find K or determine that it is not present. From the depth of this tree one can easily see that the algorithm makes no more than O(log2n)comparisons.
It is possible to consider other criteria than equal splitting for dividing the remainig file. An alternate method is Fibonacci search, which splits the subfile according to the Fibonacci sequence,
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ...
which is defined as F0 = 0, F1 = 1 and
Fi = Fi-1 + Fi-2, i
An advantage of Fibonacci search is that it involves only addition and subtraction rather than the division in BINSRCH. So its average performance is better than that of binary search on computers for which division takes sufficiently more time than addition/subtraction.
Suppose we begin by assuming that the number of records is one less than some Fibonacci number, n = Fk - 1. Then, the first comparison of key K is made with KFk-1 with the following outcomes:
(i) K < KFk-1 in which case the subfile from 1 to Fk-1 - 1 is searched and this file has one less than a Fibonacci number of records;
(ii) K = KFk-1 in which case the search terminates successfully;
(iii) K > KFk-1 in which case the subfile from Fk-1 + 1 to Fk - 1 is searched and the size of this file is Fk - 1 - (Fk-1 + 1) + 1 = Fk - Fk-1 = Fk-2 - 1.
Again it is helpful to think of this process as a binary decision tree; the resulting tree for n = 33 is given on page 340.
This tree is an example of a Fibonacci tree. Such a tree has n = Fk -1 nodes, and its left and right subtrees are also Fibonacci trees with Fk-1 - 1 and Fk-2 - 1 nodes respectively. The values in the nodes show how the file will be broken up during the searching process. Note how the values of the children differ from the parent by the same amount. Moreover, this difference is a Fibonacci number. If we look at a grandparent, parent and two children where the parent is a left child, then if the difference from grandparent to present is Fj, the next difference is Fj-1. If instead the parent is a right child then the next difference is Fj-2.
The following algorithm implements this Fibonacci splitting idea.
Getting back to our example of the telephone directory, we notice that neither of the two ordered search methods suggested above corresponds to the one actually employed by humans in searching the directory. If we are looking for a name beginning with W, we start the search towards the end of the directory rather than at the middle. A search method based on this interpolation search would then begin by comparing key Ki with
The four search procedures sequential, binary, Fibonacci and interpolation search were programmed in Fortran and their performance evaluated on a Cyber 74 computer. The results of this evaluation are presented in table 7.1. Since the input for the last three algorithms is a sorted file, algorithm SEQSRCH was modified to take advantage of this. This was achieved by changing the conditional in the while statement from Ki
As can be seen, Fibonacci search always performed worse than binary search. The performance of interpolation search is highly dependent on key value distribution. Its performance is best on uniform distributions. Its average behavior on uniform distributions was better than that for binary search for n
We have seen that as far as the searching problem is concerned, something is to be gained by maintaining the file in an ordered manner if the file is to be searched repeatedly. Let us now look at another example where the use of ordered files greatly reduces the computational effort. The problem we are now concerned with is that of comparing two files of records containing data which is essentially the same data but has been obtained from two different sources. We are concerned with verifying that the two files contain the same data. Such a problem could arise, for instance, in the case of the U.S. Internal Revenue Service which might receive millions of forms from various employers stating how much they paid their employees and then another set of forms from individual employees stating how much they received. So we have two files of records, and we wish to verify that there is no discrepancy between the information on the files. Since the forms arrive at the IRS in essentially a random order, we may assume a random arrangement of the records in the files. The key here would probably be the social security numbers. Let the records in the two files,
If one proceeded to carry out the verification directly, one would probably end up with an algorithm similar to VERIFY1.
One may readily verify that the worst case asymptotic computing time of the above algorithm is O(mn). On the other hand if we first ordered the two files and then made the comparison it would be possible to carry out the verification task in time O(tsort(n) + tsort(m) + n + m) where tsort(n) is the time needed to sort a file of n records. As we shall see, it is possible to sort n records in O(n log n) time, so the computing time becomes O(max {n log n, m log m}). The algorithm VERIFY2 achieves this.
We have seen two important uses of sorting: (i) as an aid in searching, and (ii) as a means for matching entries in files. Sorting also finds application in the solution of many other more complex problems, e.g. from operations research and job scheduling. In fact, it is estimated that over 25% of all computing time is spent on sorting with some installations spending more than 50% of their computing time sorting files. Consequently, the problem of sorting has great relevance in the study of computing. Unfortunately, no one method is the "best" for all initial orderings of the file being sorted. We shall therefore study several methods, indicating when one is superior to the others.
First let us formally state the problem we are about to consider.
We are given a file of records (R1,R2, ...,Rn). Each record, Ri, has key value Ki. In addition we assume an ordering relation (<) on the key so that for any two key values x and y either x = y or x < y or y < x. The ordering relation (<) is assumed to be transitive, i.e., for any three values x, y and z, x < y and y < z implies x < z. The sorting problem then is that of finding a permutation,
Note that in the case when the file has several key values that are identical, the permutation,
(i) K
(ii) If i < j and Ki = Kj in the input file, then Ri precedes Rj in the sorted file.
A sorting method generating the permutation
To begin with we characterize sorting methods into two broad categories: (i) internal methods, i.e., methods to be used when the file to be sorted is small enough so that the entire sort can be carried out in main memory; and (ii) external methods, i.e., methods to be used on larger files. In this chapter we shall study the following internal sorting methods:
a) Insertion sort
b) Quick sort
c) Merge sort
d) Heap sort
e) Radix sort
External sorting methods will be studied in Chapter 8.
The basic step in this method is to insert a record R into a sequence of ordered records, R1,R2, ...,Ri, (K1
Again, note that the use of Ro enables us to simplify the while loop, avoiding a test for end of file, i.e., j < 1.
Insertion sort is carried out by beginning with the ordered sequence Ro,R1, and then successively inserting the records R2,R3, ... Rn into the sequence. since each insertion leaves the resultant sequence ordered, the file with n records can be ordered making n - 1 insertions. The details are given in algorithm INSORT on the next page.
In the worst case algorithm INSERT(R,i) makes i + 1 comparisons before making the insertion. Hence the computing time for the insertion is O(i). INSORT invokes procedure INSERT for i = 1,2, ...,n - 1
resulting in an overall worst case time of
One may also obtain an estimate of the computing time of this method based upon the relative disorder in the input file. We shall say that the record Ri is left out of order (LOO) iff
Example 7.1: Assume n = 5 and the input sequence is (5,4,3,2,1) [note the records have only one field which also happens to be the key]. Then, after each insertion we have the following:
Note that this is an example of the worst case behavior.
Example 7.2: n = 5 and the input sequence is (2, 3, 4, 5, 1). After each execution of INSERT we have:
In this example only R5 is LOO and the time for each i = 2,3 and 4 is O(1) while for i = 5 it is O(n).
It should be fairly obvious that this method is stable. The fact that the computing time is O(kn) makes this method very desirable in sorting sequences where only a very few records are LOO (i.e., k << n). The simplicity of this scheme makes it about the fastest sorting method for n
We now turn our attention to a sorting scheme with a very good average behavior. The quicksort scheme developed by C. A. R. Hoare has the best average behavior among all the sorting methods we shall be studying. In Insertion Sort the key Ki currently controlling the insertion is placed into the right spot with respect to the sorted subfile (R1, ...,Ri - 1). Quicksort differs from insertion sort in that the key Ki controlling the process is placed at the right spot with respect to the whole file. Thus, if key Ki is placed in position s(i), then Kj
Example 7.3: The input file has 10 records with keys (26, 5, 37, 1, 61, 11, 59, 15, 48, 19). The table below gives the status of the file at each call of QSORT. Square brackets are used to demarcate subfiles yet to be sorted.
The worst case behavior of this algorithm is examined in exercise 5 and shown to be O(n2). However, if we are lucky then each time a record is correctly positioned, the subfile to its left will be of the same size as that to its right. This would leave us with the sorting of two subfiles each of size roughly n/2. The time required to position a record in a file of size n is O(n). If T(n) is the time taken to sort a file of n records, then when the file splits roughly into two equal parts each time a record is positioned correctly we have
In our presentation of QSORT, the record whose position was being fixed with respect to the subfile currently being sorted was always chosen to be the first record in that subfile. Exercise 6 examines a better choice for this control record. Lemma 7.1 shows that the average computing time for Quicksort is O(n log2 n). Moreover, experimental results show that as far as average computing time is concerned, it is the best of the internal sorting methods we shall be studying.
Unlike Insertion Sort where the only additional space needed was for one record,Quicksort needs stack space to implement the recursion. In case the files split evenly as in the above analysis, the maximum recursion depth would be log n requiring a stack space of O(log n). The worst case occurs when the file is split into a left subfile of size n - 1 and a right subfile of size 0 at each level of recursion. In this case, the depth of recursion becomes n requiring stack space of O(n). The worst case stack space can be reduced by a factor of 4 by realizing that right subfiles of size less than 2 need not be stacked. An asymptotic reduction in stack space can be achieved by sorting smaller subfiles first. In this case the additional stack space is at most O(log n).
Lemma 7.1: Let Tavg(n) be the expected time for QSORT to sort a file with n records. Then there exists a constant k such that Tavg(n)
Proof: In the call to QSORT (1,n), K1 gets placed at position j. This leaves us with the problem of sorting two subfiles of size j - 1 and n - j. The expected time for this is Tavg(j - 1) + Tavg(n - j). The remainder of the algorithm clearly takes at most cn time for some constant c. Since j may take on any of the values 1 to n with equal probability we have:
We may assume Tavg(0)
Induction Base: For n = 2 we have from eq. (7.1):
Tavg(2)
Induction Hypothesis: Assume Tavg(n)
Induction Step: From eq. (7.1) and the induction hypothesis we have:
Since j loge j is an increasing function of j eq. (7.2) yields:
Both of the sorting methods we have seen have a worst case behavior of O(n2) It is natural at this point to ask the question: "What is the best computing time for sorting that we can hope for?" The theorem we shall prove shows that if we restrict our question to algorithms for which the only operations permitted on keys are comparisons and interchanges then O(n log2 n) is the best possible time.
The method we use is to consider a tree which describes the sorting process by having a vertex represent a key comparison and the branches indicate the result. Such a tree is called a decision tree. A path through a decision tree represents a possible sequence of computations that an algorithm could produce.
As an example of such a tree, let us look at the tree obtained for Insertion Sort working on a file with three records in it. The input sequence is R1, R2 and R3 so the root of the tree is labeled (1,2,3). Depending on the outcome of the comparison between K1 and K2, this sequence may or may not change. If K2 < K1, then the sequence becomes (2,1,3) otherwise it stays 1,2,3. The full tree resulting from these comparisons is shown below. The leaf nodes are numbered I-VI and are the only points at which the algorithm may terminate. Hence only six permutations of the input sequence are obtainable from this algorithm. Since all six of these are different and 3! = 6, it follows that this algorithm has enough leaves to constitute a valid sorting algorithm for three records. The maximum depth of this tree is 3. The table below gives six different orderings of key values 7, 9, 10 which show that all six permutations are possble. The tree is not a full binary tree of depth 3 and so it has fewer than 23 = 8 leaves. The possible output permutations are:
The decision tree is
Theorem 7.1: Any decision tree that sorts n distinct elements has a height of at least log2(n!)+ 1.
Proof: When sorting n elements there are n! different possible results. Thus, any decision tree must have n! leaves. But a decision tree is also a binary tree which can have at most 2k-1 leaves if its height is k. Therefore, the height must be at least log2n! + 1.
Corollary: Any algorithm which sorts by comparisons only must have a worst case computing time of O(n log2 n).
Proof: We must show that for every decision tree with n! leaves there is a path of length c nlog2 n, c a constant. By the theorem, there is a path of length log2 n!. Now
so log2 n!
Before looking at the merge sort algorithm to sort n records let us see how one may merge two files (Xl, ...,Xm) and (Xm+1, ...,Xn) that are already sorted to get a third file (Zl, ...,Zn) that is also sorted. Since this merging scheme is very simple, we directly present the algorithm.
At each iteration of the while loop k increases by 1. The total increment in k is n - l + 1. Hence the while loop is iterated at most n - l + 1 times. The if statement moves at most one record per iteration. The total time is therefore O(n - l + 1). If records are of length M then this time is really O(M(n - l + 1)). When M is greater than 1 we could use linked lists (X1, ...,Xm) and (Xm+1, ...,Xn) and obtain a new sorted linked list containing these n - l + 1 records. Now, we won't need the additional space for n - l + 1 records as needed above for Z. Instead only space for n - l + 1 links is needed. The merge time becomes independent of M and is O(n - l + 1). Note that n - l + 1 is the number of records being merged.
Two-way merge sort begins by interpreting the input as n sorted files each of length 1. These are merged pairwise to obtain n/2 files of size 2 (if n is odd, then one file is of size 1). These n/2 files are then merged pairwise and so on until we are left with only one file. The example below illustrates the process.
Example 7.4.1: The input file is (26, 5, 77, 1, 61, 11, 59, 15, 15, 48, 19). The tree below illustrates the subfiles being merged at each pass:
As is apparent from the example above, merge sort consists of several passes over the records being sorted. In the first pass files of size 1 are merged. In the second, the size of the files being merged is 2. On the ith pass the files being merged are of size 2i-1.Consequently, a total of
In formally writing the algorithm for 2-way merge, it is convenient to first present an algorithm to perform one merge pass of the merge sort.
The merge sort algorithm then takes the form:
It is easy to verify that the above algorithm results in a stable sorting procedure. Exercise 10 discusses a variation of the two-way merge sort discussed above. In this variation the prevailing order within the input file is taken into account to obtain initially sorted subfiles of length
Merge sort may also be arrived at recursively. In the recursive formulation we divide the file to be sorted into two roughly equal parts called the left and the right subfiles. These subfiles are sorted using the algorithm recursively and then the two subfiles are merged together to obtain the sorted file. First, let us see how this would work on our earlier example.
Example 7.4.2: The input file (26, 5, 77, 1, 61, 11, 59, 15, 49, 19) is to be sorted using the recursive formulation of 2-way merge sort. If the subfile from l to u is currently to be sorted then its two subfiles are indexed from l to
From the preceding example, we may draw the following conclusion. If algorithm MERGE is used to merge sorted subfiles from one array into another, then it is necessary to copy subfiles. For example to merge [5, 26] and [77] we would have to copy [77] into the same array as [5, 26]. To avoid this unnecessary copying of subfiles using sequential allocation, we look to a linked list representation for subfiles. This method of representation will permit the recursive version of merge sort to work efficiently.
Each record is assumed to have two fields LINK and KEY. LINK (i) and KEY(i) are the link and key value fields in record i, 1
The algorithm RMERGE below uses a dummy record with index d. It is assumed that d is provided externally and that d is not one of the valid indexes of records i.e. d is not one of the numbers 1 through n.
One may readily verify that this linked version of 2-way merge sort results in a stable sorting procedure and that the computing time is O(n log n).
While the Merge Sort scheme discussed in the previous section has a computing time of O(n log n) both in the worst case and as average behavior, it requires additional storage proportional to the number of records in the file being sorted. The sorting method we are about to study will require only a fixed amount of additional storage and at the same time will have as its worst case and average computing time O(n log n). In this method we shall interpret the file to be sorted R = (R1, ...,Rn) as a binary tree. (Recall that in the sequential representation of a binary tree discussed in Chapter 5 the parent of the node at location i is at
Heap sort may be regarded as a two stage method. First the tree representing the file is converted into a heap. A heap is defined to be a complete binary tree with the property that the value of each node is at least as large as the value of its children nodes (if they exist) (i.e., K
Essential to any algorithm for Heap Sort is a subalgorithm that takes a binary tree T whose left and right subtrees satisfy the heap property but whose root may not and adjusts T so that the entire binary tree satisfies the heap property. Algorithm ADJUST does this.
If the depth of the tree with root i is k, then the while loop is executed at most k times. Hence the computing time of the algorithm is O(k).
The heap sort algorithm may now be stated.
Example 7.5: The input file is (26, 5, 77, 1, 61, 11, 59, 15, 48, 19). Interpreting this as a binary tree we have the following transformations:
The figures on pages 360-361 illustrate the heap after restructuring and the sorted part of the file.
Suppose 2k-1
In the next for loop n - 1 applications of ADJUST are made with maximum depth k =
Let us now look at the problem of sorting records on several keys, K1,K2, ..., Kr (K1 is the most significant key and Kr the least). A file of records R1, ...,Rn will be said to be sorted with respect to the keys K1,K2,...,Kr iff for every pair of records
For example, the problem of sorting a deck of cards may be regarded as a sort on two keys, the suit and face values, with the following ordering relations:
and face values: 2 < 3 < 4 ... < 10 < J < Q < K < A.
There appear to be two popular ways to accomplish the sort. The first is to sort on the most significant key K1 obtaining several "piles" of records each having the same value for K1. Then each of these piles is independently sorted on the key K2 into "subpiles" such that all the records in the same subpile have the same values for K1 and K2. The subpiles are then sorted on K3, etc., and the piles put together. In the example above this would mean first sorting the 52 cards into four piles one for each of the suit values. Then sort each pile on the face value. Now place the piles on top of each other to obtain the ordering: 2
A sort proceeding in this fashion will be referred to as a most significant digit first (MSD) sort. The second way, quite naturally, is to sort on the least significant digit first (LSD). This would mean sorting the cards first into 13 piles corresponding to their face values (key K2). Then, place the 3's on top of the 2's, ..., the kings on top of the queens, the aces on top of the kings; turn the deck upside down and sort on the suit (K1) using some stable sorting method obtaining four piles each of which is ordered on K2; combine the piles to obtain the required ordering on the cards.
Comparing the two procedures outlined above (MSD and LSD) one notices that LSD is simpler as the piles and subpiles obtained do not have to be sorted independently (provided the sorting scheme used for sorting on key Ki, 1
LSD and MSD only specify the order in which the different keys are to be sorted on and not the sorting method to be used within each key. The technique generally used to sort cards is a MSD sort in which the sorting on suit is done by a bin sort (i.e., four "bins" are set up, one for each suit value and the cards are placed into their corresponding "bins"). Next, the cards in each bin are sorted using an algorithm similar to Insertion Sort. However, there is another way to do this. First use a bin sort on the face value. To do this we need thirteen bins one for each distinct face value. Then collect all the cards together as described above and perform bin sort on the suits using four bins. Note that a bin solt requires only O(n) time if the spread in key values is O(n).
LSD or MSD sorting can also be used to sort records on only one logical key by interpreting this key as being composed of several keys. For example, if the keys are numeric, then each decimal digit may be regarded as a key. So if all the keys are in the range 0
Let us look in greater detail at the implementation of an LSD radix r sort. We assume that the records R1, ...,Rn have keys that are d-tuples (x1,x2, ...,xd) and 0
The algorithm makes d passes over the data, each pass taking O(n + r) time. Hence the total computing time is O(d(n + r)). In the sorting of numeric data, the value of d will depend on the choice of the radix r and also on the largest key. Different choices of r will yield different computing times (see Table 7.2).
Example 7.6: We shall illustrate the operation of algorithm LRSORT while sorting a file of 10 numbers in the range [0,999]. Each decimal digit in the key will be regarded as a subkey. So, the value of d is 3 and that of r is 10. The input file is linked and has the form given on page 365 labeled R1, ...,R10. The figures on pages 365-367 illustrates the r = 10 case and the list after the queues have been collected from the 10 bins at the end of each phase. By using essentially the method above but by varying the radix, one can obtain (see exercises 13 and 14) linear time algorithms to sort n record files when the keys are in the range 0
Apart from radix sort, all the sorting methods we have looked at require excessive data movement; i.e., as the result of a comparison, records may be physically moved. This tends to slow down the sorting process when records are large. In sorting files in which the records are large it is necessary to modify the sorting methods so as to minimize data movement. Methods such as Insertion Sort and Merge Sort can be easily modified to work with a linked file rather than a sequential file. In this case each record will require an additional link field. Instead of physically moving the record, its link field will be changed to reflect the change in position of that record in the file (see exercises 4 and 8). At the end of the sorting process, the records are linked together in the required order. In many applications (e.g., when we just want to sort files and then output them record by record on some external media in the sorted order) this is sufficient. However, in some applications it is necessary to physically rearrange the records in place so that they are in the required order. Even in such cases considerable savings can be achieved by first performing a linked list sort and then physically rearranging the records according to the order specified in the list. This rearranging can be accomplished in linear time using some additional space.
If the file, F, has been sorted so that at the end of the sort P is a pointer to the first record in a linked list of records then each record in this list will have a key which is greater than or equal to the key of the previous record (if there is a previous record), see figure 7.1. To physically rearrange these records into the order specified by the list, we begin by interchanging records R1 and RP. Now, the record in the position R1 has the smallest key. If P
Example 7.7: After a list sort on the input file (35, 18, 12, 42, 26, 14) has been made the file is linked as below (only three fields of each record are shown):
Following the links starting at RP we obtain the logical sequence of records R3, R6, R2, R5, R1, and R4 corresponding to the key sequence 12, 14, 18, 26, 35, and 42. Filling in the backward links, we have
The configuration at the end of each execution of the for loop is:
The logical sequence of the remaining list (LS) is: R6, R2, R5, R3, R4. The remaining execution yields
If there are n records in the file then the time required to convert the chain P into a doubly linked list is O(n). The for loop is iterated n-1 times. In each iteration at most two records are interchanged. This requires 3 records to move. If each record is m words long, then the cost per intgrchange is 3m. The total time is therefore O(nm). The worst case of 3(n - 1) record moves is achievable. For example consider the input key sequence R1, R2, ... Rn with R2 < R3 < ... < Rn and R1 > Rn. For n = 4 and keys 4, 1, 2, 3 the file after each iteration has the following form: i = 1: 1,4,2,3; i = /2: 1,2,4,3; i = 3: 1,2,3,4. A total of 9 record moves is made.
Several modifications to algorithm LIST1 are possible. One that is of interest was given by M. D. MacLaren. This results in a rearrangement algorithm in which no additional link fields are necessary. In this algorithm, after the record RP is exchanged with Ri the link field of the new Ri is set to P to indicate that the original record was moved. This, together with the observation that P must always be
Example 7.8: The data is the same as in Example 7.7. After the list sort we have:
After each iteration of the for loop, we have:
Now P < 3 and so it is advanced to LINK(P) = 6.
Again P < 5 and following links from Rp we find R6 to be the record with fifth smallest key.
The sequence of record moves for LIST2 is identical to that for LIST1. Hence, in the worst case 3(n - 1) record moves for a total cost of O(n m) are made. No node is examined more than once in the while loop. So the total time for the [while loop is O(n). While the asymptotic computing time for both LIST1 and LIST2 is the same and the same number of record moves is made in either case, we would expect LIST2 to be slightly faster than LIST1 because each time two records are interchanged LIST1 does more work than LIST2 does. LIST1 is inferior to LIST2 on both space and time considerations.
The list sort technique discussed above does not appear to be well suited for use with sort methods such as Quick Sort and Heap Sort. The sequential representation of the heap is essential to Heap Sort. In such cases as well as in the methods suited to List Sort, one can maintain an auxiliary table with one entry per record. The entries in this table serve as an indirect reference to the records. Let this table be T(l), T(2), ...,T(n). At the start of the sort T(i) = i, 1
Example 7.9: : Following a table sort on the file F we have the following values for T (only the key values for the 8 records of F are shown):
There are two nontrivial cycles in the permutation specified by T. The first is R1, R3, R8, R6 and R1. The second is R4, R5, R7, R4. During the first iteration (i = 1) of the for loop of algorithm TABLE, the cycle R1, RT(1), RT2(1), RT3(1), R1 is followed. Record R1 is moved to a temporary spot P. RT(1) (i.e. R3) is moved to the position R1; RT2(1) (i.e. R8) is moved to R3; R6 to R8 and finally P to R6. Thus, at the end of the first iteration we have:
For i = 2,3, T(i) = i, indicating that these records are already in their correct positions. When i = 4, the next nontrivial cycle is discovered and the records on this cycle R4, R5, R7, R4 are moved to their correct positions. Following this we have:
For the remaining values of i (i = 5, 6 and 7), T(i) = i, and no more nontrivial cycles are found.
If each record uses m words of storage then the additional space needed is m words for P plus a few more for variables such as i, j and k. To obtain an estimate of the computing time we observe that the for loop is executed n-1 times. If for some value of i, T(i)
In comparing the algorithms LIST2 and TABLE for rearranging records we see that in the worst case LIST2 makes 3(n - 1) record moves while TABLE makes only
Of the several sorting methods we have studied there is no one method that is best. Some methods are good for small n, others for large n. Insertion Sort is good when the file is already partially ordered. Because of the low overhead of the method it is also the best sorting method for "small" n. Merge Sort has the best worst case behavior but requires more storage than Heap Sort (though also an O(n log n) method it has slightly more overhead than Merge Sort). Quick Sort has the best average behavior but its worst case behavior is O(n2). The behavior of Radix Sort depends on the size of the keys and the choice of r.
These sorting methods have been programmed in FORTRAN and experiments conducted to determine the behavior of these methods. The results are summarized in Table 7.2. Table 7.2(a) gives the worst case sorting times for the various methods while table 7.2(b) gives the average times. Since the worst case and average times for radix sort are almost the same, only the average times have been reported. Table 7.2(b) contains two rows for Radix Sort. The first gives the times when an optimal radix r is used for the sort. The second row gives the times when the radix is fixed at 10. Both tables contain two rows for Insertion Sort. Comparing the two rows gives us an indication of the time saved by using a dummy key, K(0), in the algorithm as opposed to explicitly checking for the left most record (i.e. R(1)). In a separate study it was determined that for average times, Quicksort is better than Insertion Sort only when n
A comprehensive discussion of sorting and searching may be found in:
The Art of Computer Programming: Sorting and Searching, by D. Knuth, vol. 3, Addison-Wesley, Reading, Massachusetts, 1973.
Two other useful references on sorting are:
Sorting and Sort Systems by H. Lorin, Addison-Wesley, Reading, Massachusetts, 1975.
Internal sorting methods illustrated with PL/1 Programs by R. Rich, Prentice-Hall, Englewood Cliffs, 1972.
For an in depth study of quicksort and stable merge sort see:
"Quicksort" by R. Sedgewick, STAN-CS-75-492, May 1975, Computer Science Department, Stanford University.
"Stable Sorting and Merging With Optimal Space and Time Bounds" by L. Pardo, STAN-CS-74-470, December 1974, Computer Science Department, Stanford University.
1. Work through algorithms BINSRCH and FIBSRCH on an ordered file with keys (1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16) and determine the number of key comparisons made while searching for the keys 2, 10 and 15. For FIBSRCH we need the three Fibonnaci numbers F5 = 5, F6 = 8, F7 = 13.
2. [Count sort] About the simplest known sorting method arises from the observation that the position of a record in a sorted file depends on the number of records with smaller keys. Associated with each record there is a COUNT field used to determine the number of records which must precede this one in the sorted file. Write an algorithm to determine the COUNT of each record in an unordered file. Show that if the file has n records then all the COUNTs can be determined by making at most n(n - 1)/2 key comparisons.
3. The insertion of algorithm INSERT was carried out by (a) searching for the spot at which the insertion is to be made and (b) making the insertion. If as a result of the search it was decided that the insertion had to be made between Ri and Ri+1, then records Ri+1, ...,Rn were moved one space to locations Ri+2, ...,Rn+1. This was carried out in parallel with the search of (a). (a) can be sped up using the idea of BINSRCH or FIBSRCH. Write an INSERT algorithm incorporating one of these two searches.
4. Phase (b) (see exercise 3) can be sped up by maintaining the sorted file as a linked list. In this case the insertion can be made without any accompanying movement of the other records. However, now (a) must be carried out sequentially as before. Such an insertion scheme is known as list insertion. Write an algorithm for list insertion. Note that the insertion algorithms of exercises 3 and 4 can be used for a sort without making any changes in INSORT.
5. a) Show that algorithm QSORT takes O(n2) time when the input file is already in sorted order.
b) Why is Km
6. (a) The quicksort algorithm QSORT presented in section 7.3 always fixes the position of the first record in the subfile currently being sorted. A better choice for this record is to choose the record with key value which is the median of the keys of the first, middle and last record in the subfile. Thus, using this median of three rule we correctly fix the position of the record Ri with Ki = median {Km, K(m+n)/2, Kn} i.e. Ki is the second largest key e.g. median {10,5,7} = 7 = median {10,7,7}. Write a nonrecursive version of QSORT incorporating this median of three rule to determine the record whose position is to be fixed. Also, adopt the suggestion of section 7.8 and use Insertion Sort to sort subfiles of size less than 21. Show that this algorithm takes O(n log n) time on an already sorted file.
(b) Show that if smaller subfiles are sorted first then the recursion in algorithm QSORT can be simulated by a stack of depth O(log n).
7. Quicksort is an unstable sorting method. Give an example of an input file in which the order of records with equal keys is not preserved.
8. a) Write a nonrecursive merge sort algorithm using linked lists to represent sorte subfiles. Show that if n records each of size m are being sorted then the time required is only O (n log n) as no records are physically moved.
b) Use the rules of section 4.9 to automatically remove the recursion from the recursive version of merge sort.
c) Take the two algorithms written above and run them on random data for n = 100, 200, ...,1000 and compare their running times.
9. (i) Prove that algorithm MSORT is stable.
(ii) Heap sort is unstable. Give an example of an input file in which the order of records with equal keys is nto preserved.
10. In the 2-way merge sort scheme discussed in section 7.5 the sort was started with n sorted files each of size 1. Another approach would be to first make one pass over the data determining sequences of records that are in order and then using these as the initially sorted files. In this case, a left to right pass over the data of example 7.4 would result in the following partitioning of the data file into sorted subfiles. This would be followed by pairwise merging of the files until only one file remains.
Rewrite the 2-way merge sort algorithm to take into account the existing order in the records. How much time does this algorithm take on an initially sorted file? Note that the original algorithm took O(n log n) on such an input file. What is the worst case computing time of the new algorithm? How much additional space is needed? Use linked lists.
11. Does algorithm LRSORT result in a stable sort when used to sort numbers as in Example 7.6?
12. Write a sort algorithm to sort records R1, ...,Rn lexically on keys (K1, ...,Kr) for the case when the range of each key is much lager than n. In this case the bin sort scheme used in LRSORT to sort within each key becomes inefficienct (why?). What scheme would you use to sort within a key if we desired an algorithm with
a) good worst case behavior
b) good average behavior
c) n is small, say < 15.
13. If we have n records with integer keys in the range [0, n2), then they may be sorted in O(n log n) time using heap or merge sort. Radix sort on a single key, i.e., d = 1 and r = n2 takes O(n2) time. Show how to interpret the keys as 2 subkeys so that radix sort will take only O(n) time to sort n records. (Hint: each key, Ki, may be written as
14. Generalize the method of the previous exercise to the case of integer keys in the range [0, np) obtaining O(pn) sorting method.
15. Write the status of the following file F at the end of each phase of the following algorithms;
a) INSORT
b) QSORT
c) MSORT
d) HSORT
e) LSORT - radix 10
F = (12, 2, 16, 30, 8, 28, 4, 10, 20, 6, 18)
16. Write a table sort version of quicksort. Now during the sort, records are not physically moved. Instead, T(i) is the index of the record that would have been in position i if records were physically moved around as in algorithm QSORT. To begin with T(i) = i, 1
17. Write an algorithm similar to algorithm TABLE to rearrange the records of a file if with each record we have a COUNT of the number of records preceding it in the sorted file (see Exercise 2).
18. Under what conditions would a MSD Radix sort be more efficient than an LSD Radix sort?
19. Assume you are given a list of five-letter English words and are faced with the problem of lisitng out these words in sequences such that the words in each sequence are anagrams, i.e., if x and y are in the same sequence, then word x is a permutation of word y. You are required to list out the fewest such sequences. With this restriction show that no word can appear in more than one sequence. How would you go about solving this problem?
20. Assume you are working in the census department of a small town where the number of records, about 3,000, is small enough to fit into the internal memory of a computer. All the people currently living in this town were born in the United States. There is one record for each person in this town. Each record contains
i) the state in which the person was born;
ii) county of birth;
iii) name of person.
How would you produce a list of all persons living in this town? The list is to be ordered by state. Within each state the persons are to be listed by their counties. The counties being arranged in aphabetical order. Within each county the names are also listed in alphabetical order. Justify any assumptions you may make.
procedure SEQSRCH(F,n,i,K)
//Search a file F with key values K1, ...,Kn for a record Ri such
that Ki = K. If there is no such record, i is set to 0//
K0
 K; i n
K; i nwhile Ki
 K do
K doi
i - 1end
end SEQSRCH
 1
1 i n (n - i + 1) / n = (n + 1)/2. For large n this many comparisons is very inefficient. However, we all know that it is possible to do much better when looking up phone numbers. What enables us to make an efficient search? The fact that the entries in the file (i.e., the telephone directory) are in lexicographic order (on the name key) is what enables one to look up a number while examining only a very few entries in the file. So, if the file is ordered one should be able to search for specific records quickly.
i n (n - i + 1) / n = (n + 1)/2. For large n this many comparisons is very inefficient. However, we all know that it is possible to do much better when looking up phone numbers. What enables us to make an efficient search? The fact that the entries in the file (i.e., the telephone directory) are in lexicographic order (on the name key) is what enables one to look up a number while examining only a very few entries in the file. So, if the file is ordered one should be able to search for specific records quickly. n/2k
n/2k (n is the number of records). Hence, in the worst case, this method requires O (log n) key comparisons to search a file. Algorithm BINSRCH implements the scheme just outlined.
(n is the number of records). Hence, in the worst case, this method requires O (log n) key comparisons to search a file. Algorithm BINSRCH implements the scheme just outlined.procedure BINSRCH(F,n,i,K)
//Search an ordered sequential file F with records R1, ...,Rn and
the keys K1
K2  Kn for a record Ri such that Ki = K;
Kn for a record Ri such that Ki = K;i = 0 if there is no such record else Ki = K. Throughout the
algorithm, l is the smallest index such that Kl may be K and u
the largest index such that Ku may be K//
l
1; u nwhile l
u dom
 (l+ u)/2
(l+ u)/2 //compute index of middle record//
//compute index of middle record//case
:K > Km: l
m + 1 //look in upper half//:K = Km: i
m; return:K < Km: u
m - 1 //look in lower half//end
end
i
0 //no record with key K//end BINSRCH
(1 + 31) / 2 = 16. If K is less than K16, then K8 is tested next (1 + 15) / 2 = 8; or if K is greater than K16, then K24 is tested. The binary tree describing this process is
 2.
2.procedure FlBSRCH(G,n,i,K)
//search a sequential file G with keys ordered in nondecreasing order,
for a record Ri with key Ki = K. Assume that Fk + m = n + 1,
m
0 and Fk + 1 > n + 1. n is the number of records in G. Fkand Fk+1 are consecutive Fibonacci numbers. If K is not present,
i is set to zero.//
i
Fk-1; p Fk-2; q Fk-3if K > Ki then [//set i so that size of the right subfile is Fk-2//
i
i + m]while i
0 docase
:K < Ki: if q = 0 then i
0else [i
i; - q; t p; p q; q t -q]:K = Ki: return
:K > Ki: if p = 1 then i
0else [i
i + q; p p - q;q q - p]end
end
end FIBSRCH
 are the values of the smallest and largest keys in the file). The behavior of such an algorithm will clearly depend on the distribution of the keys in the file. K to Ki > K and introducing an additional test after the end of the while to determine whether Ki = K. The inferior sequential method referred to in the table differs from the SEQSRCH just described in that the line Ko K is not included and a test for i < 1 is made in the while loop. As the table indicates, inferior sequential search takes almost twice as much time as normal sequential search. For average behavior, binary search is better than sequential search for n > 15, while for worst case behavior binary search is better than a sequential search for n > 4.
are the values of the smallest and largest keys in the file). The behavior of such an algorithm will clearly depend on the distribution of the keys in the file. K to Ki > K and introducing an additional test after the end of the while to determine whether Ki = K. The inferior sequential method referred to in the table differs from the SEQSRCH just described in that the line Ko K is not included and a test for i < 1 is made in the while loop. As the table indicates, inferior sequential search takes almost twice as much time as normal sequential search. For average behavior, binary search is better than sequential search for n > 15, while for worst case behavior binary search is better than a sequential search for n > 4.
Fibonacci search with n = 33
500. and
and  be (
be ( ) and (
) and ( ). The corresponding keys are
). The corresponding keys are  and
and  . Let us make the following assumptions about the required verification: (i) if corresponding to a key
. Let us make the following assumptions about the required verification: (i) if corresponding to a key  in the employer file there is no record in the employee file a message is to be sent to the employee; (ii) if the reverse is true, then a message is to be sent to the employer; and (iii) if there is a discrepancy between two records with the same key a message to that effect is to be output.
in the employer file there is no record in the employee file a message is to be sent to the employee; (ii) if the reverse is true, then a message is to be sent to the employer; and (iii) if there is a discrepancy between two records with the same key a message to that effect is to be output.
(a) Worst case times

(b) Average times obtained by searching for each key once and averaging
Table 7.1 Worst case and average times for different search methods. All times are in milliseconds. (Table prepared by Randall Istre)

 , such that K(1) K(i+1), 1 i n - 1. The desired ordering is then (R(1),R(2), ...,R(n))., defined above is not unique. We shall distinguish one permutation, s, from all the others that also order the file. Let s be the permutation with the following properties:s(i) Ks(i+1),1 i n - 1.s will be said to be stable.
, such that K(1) K(i+1), 1 i n - 1. The desired ordering is then (R(1),R(2), ...,R(n))., defined above is not unique. We shall distinguish one permutation, s, from all the others that also order the file. Let s be the permutation with the following properties:s(i) Ks(i+1),1 i n - 1.s will be said to be stable.7.2 INSERTION SORT
K2, ..., Ki) in such a way that the resulting sequence of size i + 1 is also ordered. The algorithm below accomplishes this insertion. It assumes the existence of an artificial record Ro with key Ko = - 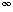 (i.e., all keys are Ko).
(i.e., all keys are Ko).procedure INSERT (R,i)
//Insert record R with key K into the ordered sequence Ro, ...,Ri
in such a way that the resulting sequence is also ordered on key
K. We assume that Ro is a record (maybe a dummy) such that
K
Ko//j
iwhile K < Kj do
//move Rj one space up as R is to be inserted left of Rj//
Rj+1
Rj; j j - 1end
Rj+1
Rend INSERT
Analysis of INSERTION SORT
procedure INSORT(R,n)
//sort the records R1, ...,Rn in nondecreasing value of the key K.
Assume n > 1//
Ko
- //Create a dummy record Ro such that Ko < Ki,1
i n//for j
2 to n doT
Rjcall INSERT(T, j - 1) //insert records R2 to Rn//
end
end INSORT
 .
. . Clearly, the insertion step has to be carried out only for those records that are LOO. If k is the number of records LOO, then the computing time is O((k + 1)n). The worst case time is still O(n2). One can also show that O(n2) is the average time.
. Clearly, the insertion step has to be carried out only for those records that are LOO. If k is the number of records LOO, then the computing time is O((k + 1)n). The worst case time is still O(n2). One can also show that O(n2) is the average time.-
, 5, 4, 3, 2, 1 [initial sequence]-
, 4, 5, 3, 2, 1 i = 2-
, 3, 4, 5, 2, 1 i = 3-
, 2, 3, 4, 5, 1 i = 4-
, 1, 2, 3, 4, 5 i = 5-
, 2, 3, 4, 5, 1 [initial]-
, 2, 3, 4, 5, l i = 2-
, 2, 3, 4, 5, 1 i = 3-
, 2. 3, 4, 5, 1 i = 4-
, 1, 2, 3, 4, 5 i = 5 20 - 25 elements, depending upon the implementation and machine properties. For variations on this method see exercises 3 and 4.7.3 QUICKSORT
Ks(i) for j < s(i) and Kj Ks(i) for j > s(i). Hence after this positioning has been made, the original file is partitioned into two subfiles one consisting of records R1, ...,Rs(i)-1 and the other of records Rs(i)+ 1, ...,Rn. Since in the sorted sequence all records in the first subfile may appear to the left of s(i) and all in the second subfile to the right of s(i), these two subfiles may be sorted independently. The method is best stated recursively as below and where INTERCHANGE (x,y) performs t x; x y; y t.procedure QSORT(m,n)
//sort records Rm, ...,Rn into nondecreasing order on key K. Key
Km is arbitrarily chosen as the control key. Pointers i and j are
used to partition the subfile so that at any time Kl
K, l < iand Kl
K, l > j. It is assumed that Km Kn+1//if m < n
then [i
m; j n + 1; K Kmloop
repeat i
i + 1 until Ki K;repeat j
j - 1 until Kj K;if i < j
then call INTERCHANGE (R(i),R(j))
else exit
forever
call INTERCHANGE (R(m),R(j))
call QSORT (m,j - 1)
call QSORT (j + 1, n)]
end QSORT
R1 R2 R3 R4 R5 R6 R7 R8 R9 Rl0 m n
[26 5 37 1 61 11 59 15 48 19] 1 10
[11 5 19 1 15] 26 [59 61 48 37] 1 5
[ 1 5] 11 [19 15] 26 [59 61 48 37] 1 2
1 5 11 [19 15] 26 [59 61 48 37] 4 5
1 5 11 15 19 26 [59 61 48 37] 7 10
1 5 11 15 19 26 [48 37] 59 [61] 7 8
1 5 11 15 19 26 37 48 59 [61] 10 10
1 5 11 l5 l9 26 37 48 59 6l
Analysis of Quicksort
T(n)
cn + 2T(n/2) , for some constant c cn + 2(cn/2 + 2T(n/4)) 2cn + 4T(n/4):
cn log2n + nT(1) = O(n log2 n) k n 1oge n for n 2. 
(7.1)
b and Tavg(1) b for some constant b. We shall now show Tavg(n) kn 1oge n for n 2 and k = 2(b + c). The proof is by induction on n. 2c + 2b kn loge2 kn 1ogen for 1 n < m
(7.2)

7.4 HOW FAST CAN WE SORT?
SAMPLE INPUT KEY VALUES WHICH
LEAF PERMUTATION GIVE THE PERMUTATION
I 1 2 3 (7,9,10)
II 1 3 2 (7,10,9)
III 3 1 2 (9,10,7)
IV 2 1 3 (9,7,10)
V 2 3 1 (10,7,9)
VI 3 2 1 (10,9,7)

n! = n(n - 1)(n - 2) ... (3)(2)(1)
(n/2)n/2, (n/2) log2 (n/2) = O(n log2 n). 7.5 2-WAY MERGE SORT
procedure MERGE(X,l,m,n,Z)
//(Xl, ...,Xm) and (Xm+1, ...,Xn) are two sorted files with keys
xl
... xm and Xm+1 ... xn. They are merged to obtain thesorted file (Zl, ..., Zn) such that zl
... zn//i
k l; j m + 1 //i, j and k are position in the three files//while i
m and j n doif xi
xj then [Zk Xi; i i + 1]else [Zk
Xj; j j + 1]k
k + 1end
if i > m then (Zk, ...,Zn)
(Xj, ...,Xn)else (Zk, ...,Zn)
(Xi ...,Xm)end MERGE
Analysis of Algorithm MERGE
 log2 n passes are made over the data. Since two files can be merged in linear time (algorithm MERGE), each pass of merge sort takes O(n) time. As there are log2 n passes, the total computing time is O(n log n).
log2 n passes are made over the data. Since two files can be merged in linear time (algorithm MERGE), each pass of merge sort takes O(n) time. As there are log2 n passes, the total computing time is O(n log n).procedure MPASS(X,Y,n,l)
//This algorithm performs one pass of merge sort. It merges adjacent
pairs of subfiles of length l from file X to file Y. n is the number
of records in X//
i
1while i
n - 2l + 1 docall MERGE (X, i, i + l - 1, i + 2l - 1, Y)
i
i + 2lend
//merge remaining file of length <2l//
if i + l - 1 < n then call MERGE (X, i, i + l - 1, n, Y)
else (Yi, ...Yn)
(Xi, ...,Xn)end MPASS
procedure MSORT(X,n)
//Sort the file X = (X1, ...,Xn) into nondecreasing order of the keys
x1, ...,xn//
declare X(n), Y(n) //Y is an auxilliary array//
//l is the size of subfiles currently being merged//
l
1while l < n do
call MPASS(X,Y,n,l)
l
2*lcall MPASS(Y,X,n,l) //interchange role of X and Y//
l
2*lend
end MSORT
1.Recursive Formulation of Merge Sort
(l + u)/2 and from (l + u)/2 + 1 to u. The subfile partitioning that takes place is described by the following binary tree. Note that the subfiles being merged are different from those being merged in algorithm MSORT. i n. We assume that initially LINK(i) = 0, 1 i n. Thus each record is initially in a chain containing only itself. Let Q and R be pointers to two chains of records. The records on each chain are assumed linked in nondecreasing order of the key field. Let RMERGE(Q,R,P) be an algorithm to merge the two chains Q and R to obtain P which is also linked in nondecreasing order of key values. Then the recursive version of merge sort is given by algorithm RMSORT. To sort the records X1, ...,Xn this algorithm is invoked as call RMSORT(X,1,n,P). P is returned as the start of a chain ordered as described earlier. In case the file is to be physically rearranged into this order then one of the schemes discussed in section 7.8 may be used.
i n. We assume that initially LINK(i) = 0, 1 i n. Thus each record is initially in a chain containing only itself. Let Q and R be pointers to two chains of records. The records on each chain are assumed linked in nondecreasing order of the key field. Let RMERGE(Q,R,P) be an algorithm to merge the two chains Q and R to obtain P which is also linked in nondecreasing order of key values. Then the recursive version of merge sort is given by algorithm RMSORT. To sort the records X1, ...,Xn this algorithm is invoked as call RMSORT(X,1,n,P). P is returned as the start of a chain ordered as described earlier. In case the file is to be physically rearranged into this order then one of the schemes discussed in section 7.8 may be used.procedure RMSORT(X,l,u,P)
//The file X = (Xl, ...,Xu) is to be sorted on the field KEY. LINK
is a link field in each record and is initially set to 0. The sorted
file is a chain beginning at P//
if l
u then P lelse [mid
(l + u)/2call RMSORT(X,l,mid,Q)
call RMSORT(X,mid + 1,u,R)
call RMERGE(Q,R,P)]
end RMSORT
procedure RMERGE(X,Y,Z)
//The linked files X and Y are merged to obtain Z. KEY(i) denotes
the key field and LINK(i) the link field of record i. In X, Y and
Z the records are linked in order of nondecreasing KEY values.
A dummy record with index d is made use of. d is not a valid
index in X or Y//
i
X; j Y; z dwhile i
0 and j 0 doif KEY(i)
KEY(j) then [LINK(z) iz
i; i LINK (i)]else [LINK(z)
jz
j; j LINK(j)]end
//move remainder//
if i = 0 then LINK(z)
jelse LINK(z)
iZ
LINK(d)end RMERGE
7.6 HEAP SORT
i/2, the left child at 2i and the right child at 2i + 1. If 2i or 2i + 1 is greater than n (the number of nodes), then the corresponding children do not exist.) Thus, initially the file is interpreted as being structured as below: j/2 Kj for 1 j/2 < j n). This implies that the root of the heap has the largest key in the tree. In the second stage the output sequence is generated in decreasing order by successively outputting the root and restructuring the remaining tree into a heap.
j/2 Kj for 1 j/2 < j n). This implies that the root of the heap has the largest key in the tree. In the second stage the output sequence is generated in decreasing order by successively outputting the root and restructuring the remaining tree into a heap.procedure ADJUST (i,n)
//Adjust the binary tree with root i to satisfy the heap property.
The left and right subtrees of i, i.e., with roots 2i and 2i+ 1, already
satisfy the heap property. The nodes of the trees contain records,
R, with keys K. No node has index greater than n//
R
Ri; K Ki; j 2iwhile j
n doif j < n and Kj < Kj+1 then j
j + 1 //find max of leftand right child//
//compare max. child with K. If K is max. then done//
if K
Kj then exitR
j/2 Rj; j 2j //move Rj up the tree//end
R
j/2 Rend ADJUST
Analysis of Algorithm Adjust
procedure HSORT (R,n)
//The file R = (R1, ...,Rn) is sorted into nondecreasing order of
the key K//
for i
n/2 to 1 by -1 do //convert R into a heap//call ADJUST (i,n)
end
for i
n - 1 to 1 by -1 do //sort R//T
Ri+1; Ri+1 R1; R1 T //interchange R1 and Ri+1//call ADJUST (1,i) //recreate heap//
end
end HSORT

Analysis of Algorithm HSORT
n < 2k so that the tree has k levels and the number of nodes on level i is 2i-1. In the first for loop ADJUST is called once for each node that has a child. Hence the time required for this loop is the sum, over each level, of the number of nodes on a level times the maximum distance the node can move. This is no more than log2 (n + 1). Hence the computing time for this loop is O(n log n). Consequently, the total computing time is O(n log n). Note that apart from pointer variables, the only additional space needed is space for one record to carry out the exchange in the second for loop. Note also that instead of making the exchange, one could perform the sequence R Ri+1, Ri+1 R1 and then proceed to adjust the tree.
log2 (n + 1). Hence the computing time for this loop is O(n log n). Consequently, the total computing time is O(n log n). Note that apart from pointer variables, the only additional space needed is space for one record to carry out the exchange in the second for loop. Note also that instead of making the exchange, one could perform the sequence R Ri+1, Ri+1 R1 and then proceed to adjust the tree.7.7 SORTING ON SEVERAL KEYS
 . The r-tuple (x1, ...,xr) is less than or equal to the r-tuple (y1, ...,yr) iff either xi = yi, 1 i j and xj+1 < yj+1 for some j r or xi = yi, 1 i r.
. The r-tuple (x1, ...,xr) is less than or equal to the r-tuple (y1, ...,yr) iff either xi = yi, 1 i j and xj+1 < yj+1 for some j r or xi = yi, 1 i r.


 , ...,A , ..., ...,2
, ...,A , ..., ...,2  , ...,A . i < r < is stable). This in turn implies less overhead. K 999, then we can use either the LSD or MSD sorts for three keys (K1,K2,K3), where K1 is the digit in the hundredths place, K2 the digit in the tens place, and K3 that in the units place. Since all the keys lie in the range 0 Ki 9, the sort within the keys can be carried out using a bin sort with ten bins. This, in fact, is essentially the process used to sort records punched on cards using a card sorter. In this case using the LSD process would be more convenient as it eliminates maintaining several independent subpiles. If the key is interpreted as above, the resulting sort is called a radix 10 sort. If the key decomposition is carried out using the binary representation of the keys, then one obtains a radix 2 sort. In general, one could choose any radix r obtaining a radix r sort. The number of bins required is r. xi < r. Thus, we shall need r bins. The records are assumed to have a LINK field. The records in each bin will be linked together into a linear linked list with F(i), 0 i < r, a pointer to the first record in bin i and E(i) a pointer to the last record in bin i. These lists will essentially be operated as queues. Algorithm LRSORT formally presents the LSD radix r method.
, ...,A . i < r < is stable). This in turn implies less overhead. K 999, then we can use either the LSD or MSD sorts for three keys (K1,K2,K3), where K1 is the digit in the hundredths place, K2 the digit in the tens place, and K3 that in the units place. Since all the keys lie in the range 0 Ki 9, the sort within the keys can be carried out using a bin sort with ten bins. This, in fact, is essentially the process used to sort records punched on cards using a card sorter. In this case using the LSD process would be more convenient as it eliminates maintaining several independent subpiles. If the key is interpreted as above, the resulting sort is called a radix 10 sort. If the key decomposition is carried out using the binary representation of the keys, then one obtains a radix 2 sort. In general, one could choose any radix r obtaining a radix r sort. The number of bins required is r. xi < r. Thus, we shall need r bins. The records are assumed to have a LINK field. The records in each bin will be linked together into a linear linked list with F(i), 0 i < r, a pointer to the first record in bin i and E(i) a pointer to the last record in bin i. These lists will essentially be operated as queues. Algorithm LRSORT formally presents the LSD radix r method.Analysis of LRSORT
procedure LRSORT(R,n,d)
//records R = (R1, ...,Rn) are sorted on the keys K1, ...,Kd. The
range of each key is 0
Ki < r. Sorting within a key is done usingbin sort. All records are assumed to be initially linked together
such that LINK(i) points to Ri+1, 1
i n and LINK(n) = 0.//declare E(0:r - 1), F(0:r - 1) //queue pointers//
p
1 //pointer to start of list of records//for i
d to 1 by - 1 do //sort on key Ki//for j
0 to r - 1 do //initialize bins to be empty queues//F(j)
0end
while p
0 do //put records into queues//k
 //k is the i-th key of p-th record//
//k is the i-th key of p-th record//if F(k) = 0 then F(k)
p //attach record p into bin k//else LINK(E(k))
pE(k)
pp
LINK(p) //get next record//end
j
0; while F(j) = 0 do j j + 1 end //find first nonemptyqueue//
p
F(j); t E(j)for k
j + 1 to r - 1 do //concatenate remaining queues//if F(k)
0 then [LINK(t) F(k); t E(k)]end
LINK(t)
0end
end LRSORT
Ki < nk for some constant k.


7.8 PRACTICAL CONSIDERATIONS FOR INTERNAL SORTING
1 then there is some record in the list with link field = 1. If we could change this link field to indicate the new position of the record previously at position 1 then we would be left with records R2, ...,Rn linked together in nondecreasing order. Repeating the above process will, after n - 1 iterations, result in the desired rearrangement. The snag, however, is that in a singly linked list we do not know the predecessor of a node. To overcome this difficulty, our first rearrangement algorithm LIST1, begins by converting the singly linked list P into a doubly linked list and then proceeds to move records into their correct places.
Figure 7.1 List Sort
procedure LIST1(R,n,P)
//P is a pointer to a list of n sorted records linked together by the
field LINK. A second link field, LINKB, is assumed to be present
in each record. The records are rearranged so that the resulting
records R1, ..., Rn are consecutive and sorted//
u
0; s Pwhile s
0 do //convert P into a doubly linked list using LINKB//LINKB(s)
u //u follows s//u
s; s LINK(s)end
for i
1 to n - 1 do //move RP to position i while//if P
i //maintaining the list//then [if LINK (i)
0 then LINKB(LINK (i)) PLINK(LINKB(i))
P; A RPRP
Ri; Ri A]P
LINK(i) //examine the next record//end
end LIST1
R1 R2 R3 R4 R5 R6
Key 35 18 12 42 26 14
LINK 4 5 6 0 1 2 P = 3
LINK B
R1 R2 R3 R4 R5 R6
35 18 12 42 26 14
4 5 6 0 1 2 P = 3
5 6 0 1 2 3
12 18 35 42 26 14
6 5 4 0 3 2 P = 6
0 6 5 3 2 3
i = 1
12 14 35 42 26 18
6 6 4 0 3 5 P = 6
0 3 5 3 6 6
LS: R6. R5, R3, R4 i = 2
12 14 18 42 26 35
6 6 5 0 6 4 P = 5
0 3 6 6 6 5
LS: R5, R6, R4 i = 3
12 14 18 26 42 35
6 6 5 6 0 5 P = 6
0 3 6 6 6 5
LS: R6, R5, i = 4
12 14 18 26 35 42
6 6 5 6 6 0 P = 6
0 3 6 6 5 6
LS: R6, i = 5
Analysis of Algorithm LIST1
i, permits a correct reordering of the records. The computing time remains O(nm).procedure LIST2 (R,n,P)
//Same function as LIST1 except that a second link field LINKB
is not reguired//
for i
1 to n - 1 do//find correct record to place into i'th position. The index of this
record must be
i as records in positions 1,2, ...,i -1 are alreadycorrectly positioned//
while P < i do
P
LINK (P)end
Q
LINK (P) //RQ is next record with largest key//if P
i then [//interchange Ri and Rp moving Rp to its correctspot as Rp has i'th smallest key. Also set link from
old position of Ri to new one// T
Ri Ri Rp; Rp TLINK (i)
P]P
Qend
end LIST2
R1 R2 R3 R4 R5 R6
Key 35 18 12 42 26 14
LINK 4 5 6 0 1 2 P = 3
12 18 35 42 26 14
3 5 4 0 3 2 P = 6
i = 1
12 14 35 42 26 18
3 6 4 0 1 5 P = 2
i = 2
12 14 18 42 26 35
3 6 6 0 1 4 P = 5
i = 3
12 14 18 26 42 35
3 6 6 5 0 4 P = 1
i = 4
12 14 18 26 35 42
3 6 6 5 6 0 P = 4
i = 5
Analysis of Algorithm LIST2
i n. If the sorting algorithm requires an interchange of Ri and Rj, then only the table entries need be interchanged, i.e., T(i) and T(j). At the end of the sort, the record with the smallest key is RT(1) and that with the largest RT(n). In general, following a table sort RT(i) is the record with the i'th smallest key. The required permutation on the records is therefore RT(1), RT(2), ...,RT(n) (see Figure 7.2). This table is adequate even in situations such as binary search, where a sequentially ordered file is needed. In other situations, it may be necessary to physically rearrange the records according to the permutation specified by T. The algorithm to rearrange records corresponding to the permutation T(1), T(2), ...,T(n) is a rather interesting application of a theorem from mathematics: viz, every permutation is made up of disjoint cycles. The cycle for any element i is made up of i, T(i), T2(i), ...,Tk(i), (where Tj(i) = T(Tj-1 (i)) and To(i) = i) such that Tk(i) = i. Thus, the permutation T of figure 7.2 has two cycles, the first involving R1 and R5 and the second involving R4, R3 and R2. Algorithm TABLE utilizes this cyclic decomposition of a permutation. First, the cycle containing R1 is followed and all records moved to their correct positions. The cycle containing R2 is the next one examined unless this cycle has already been examined. The cycles for R3, R4, ...,Rn-1 are followed in that order, achieving a reordering of all the records. While processing a trivial cycle for Ri (i.e. T(i) = i), no rearrangement involving record Ri is required since the condition T(i) = i means that the record with the i'th smallest key is Ri. In processing a nontrivial cycle for record Ri (i.e. T(i) i), Ri is moved to a temporary position P, then the record at T(i) is moved to (i); next the record at T(T(i)) is moved to T(i); and so on until the end of the cycle Tk(i) is reached and the record at P is moved to Tk-1 (i).
Figure 7.2 Table Sort
procedure TABLE(R,n,T)
//The records R1, ...,Rn are rearranged to correspond to the sequence
RT(1), ...,RT(n), n
1//for i
1 to n - 1 doif T(i)
i then //there is a nontrivial cycle starting at i//[P
Ri; j i //move Ri to a temporary spot P and follow//repeat //cycle i, T(i), T(T(i)), ... until the correct spot//
k
T(j)Rj
RkT(j)
jj
kuntil T(j) = i
Rj
P //j is position for record P//T(j)
j]end
end TABLE
R1 R2 R3 R4 R5 R6 R7 R8
F 35 14 12 42 26 50 31 18
T 3 2 8 5 7 1 4 6
F 12 14 18 42 26 35 31 50
T 1 2 3 5 6 7 4 8
F 12 14 18 26 31 35 42 50
T 1 2 3 5 7 6 4 8
Analysis of Algorithm TABLE
i then there is a nontrivial cycle including k > 1 distinct records Ri, RT(i), ...,RTk-1(i). Rearranging these records requires k + 1 record moves. Following this, the records involved in this cycle are not moved again at any time in the algorithm since T(j) = j for all such records Rj. Hence no record can be in two different nontrivial cycles. Let kl be the number of records on a nontrivial cycle starting at Rl when i = l in the algorithm. Let kl = 0 for a trivial cycle. Then, the total number of record moves is  . Since the records on nontrivial cycles must be different, kl n. The total record moves is thus maximum when kl = n and there are n/2 cycles. When n is even, each cycle contains 2 records. Otherwise one contains three and the others two. In either case the number of record moves is 3n/2. One record move costs O(m) time. The total computing time is therefore O(nm). 3n/2 record moves. For larger values of m it would therefore be worthwhile to make one pass over the sorted list of records creating a table T corresponding to a table sort. This would take O(n) time. Then algorithm TABLE could be used to rearrange the records in the order specified by T.
. Since the records on nontrivial cycles must be different, kl n. The total record moves is thus maximum when kl = n and there are n/2 cycles. When n is even, each cycle contains 2 records. Otherwise one contains three and the others two. In either case the number of record moves is 3n/2. One record move costs O(m) time. The total computing time is therefore O(nm). 3n/2 record moves. For larger values of m it would therefore be worthwhile to make one pass over the sorted list of records creating a table T corresponding to a table sort. This would take O(n) time. Then algorithm TABLE could be used to rearrange the records in the order specified by T. n
 10 20 50 100 250 500 1000
10 20 50 100 250 500 1000Quicksort [with median of 3]
(File: [N,1,2,3, ...,
N - 2, N - 1]) .499 1.26 4.05 12.9 68.7 257. 1018.
Quicksort [without median
of 3] (File: [1,2,3, ...,
N - 1, N]) .580 1.92 9.92 38.2 226. 856. 3472.
Insertion Sort
[with K(0) = -
] (File: [N,N - 1, ...,2,1]) .384 1.38 8.20 31.7 203. 788. --
Insertion Sort
[without K(0) = -
] (File: [N,N - 1, ...,2,1]) .382 1.48 9.00 35.6 214. 861. --
Heap Sort .583 1.52 4.96 11.9 36.2 80.5 177.
Merge Sort .726 1.66 4.76 11.3 35.3 73.8 151
(a) Worst case times m milliseconds
n
10 20 50 100 250 500 1000Radix Sort
(L.S.D.)
(RD
1.82 3.05 5.68 9.04 20.1 32.5 58.0 100,000;
optimal
D & R) R = 18; R = 18; R = 47; R = 47; R = 317; R = 317; R = 317;
D = 4 D = 4 D = 3 D = 3 D = 2 D = 2 D = 2
Radix Sort
(L.S.D.)
R = 10,
D = 5) 1.95 3.23 6.97 13.2 32.1 66.4 129.
Quicksort
[with
median
of 3] .448 1.06 3.17 7.00 20.0 43.1 94.9
Quicksort
[without
median
of 3] .372 .918 2.89 6.45 20.0 43.6 94.0
Insertion
Sort .232 .813 4.28 16.6 97.1 385. --
Insertion
Sort
(without
K(0) = -
) .243 .885 4.72 18.5 111. 437. --Heap Sort .512 1.37 4.52 10.9 33.2 76.1 166.
Merge Sort .642 1.56 4.55 10.5 29.6 68.2 144.
(b) Average times in milliseconds
Table 7.2 Computing times for sorting methods. (Table prepared by Randall Istre)
23 and that for worst case times Merge Sort is better than Insertion Sort only when n 25. The exact cut off points will vary with different implementations. In practice, therefore, it would be worthwhile to couple Insertion Sort with other methods so that subfiles of size less than about 20 are sorted using Insertion Sort.REFERENCES
EXERCISES
Kn+1 required in QSORT?
 with
with  and
and  integers in the range [0, n).) i n. At the end of the sort T(i) is the index of the record that should be in the i'th position in the sorted file. So now algorithm TABLE of section 7.8 may be sued to rearrange the records into the sorted order specified by T. Note that this reduces the amount of data movement taking place when compared to QSORT for the case of large records.
integers in the range [0, n).) i n. At the end of the sort T(i) is the index of the record that should be in the i'th position in the sorted file. So now algorithm TABLE of section 7.8 may be sued to rearrange the records into the sorted order specified by T. Note that this reduces the amount of data movement taking place when compared to QSORT for the case of large records.