Notice that each time through the loop, the program must select an object with no predecessors. To do this requires kdnowing which of the objects left in S have zero predecessors. Suppose that it is known, before and after each execution of the loop body, exactly how many predecessors each remaining object has. With this knowledge, an object with zero predecessor count can be selected. Once an object becomes eligible to be selected (has zero predecessors), it remains eligible until it is actually selected. Why not collect all those initially eligible in the initialization for phase II? The program could then select among them arbitrarily. Think of this collection as kept in a bag from which the object selected for output is pulled.
As the rest of the loop body is executed, the records must be updated to reflect the removal of this object and its arrows. Removing its arrows amounts to reducing the predecessor count of each successor of the object removed.Whenever the predecessor count of one of these successors becomes zero, that successor becomes eligible for selection on the next repetition of the loop. That successor is immediately added to the bag. Consequently, at the start of each loop repetition, the bag will contain exactly those objects eligible for selection, thus eliminating the need to search for them. In fact, the "S not empty" test is now equivalent to asking if the "bag is not empty." Keeping track of the successors of each object eliminates the need to search for them when that object is output. Incidently, we now know two operations that will be needed on the count collection, decrease(i,count) and iszero(i,count). The first reduces the count of the ith object by one, and the second returns true only if the count of the ith object is zero. The precise information needed for processing has now been isolated. What must be known are the predecessor counts and successors for each object, and what's in the bag.
The loop body of phase I must update predecessor counts and successors.The input pair i, j contains the information that j has one more predecessor than currently reflected in j's predecessor count, and that i has one more successor, j, than currently reflected by i's successors. The loop body of phase II must update the predecessor counts of all successors of the removed object. It must also update the bag. We have developed the following better refinement of the algorithm.
A better refinement:
1. Read n.
2. Initialize
a. Initialize the predecessor counts for each of the n objects to zero.
b. Initialize current successors for each of the n objects to zero.
3. While there is another input pair,
a. increase the predecessor count of j by l;
b. add j to the current successors of i.
4. Place all objects with zero predecessor count into the bag.
5. While the bag is not empty,
a. remove an object from the bag and output it in the output ranking;
b. for each successor of the output object, decrease its predecessor count by l; if the predecessor count becomes zero, add the successor to the bag.
The implementation treats the predecessor counts, the collections of successor counts, the bag, and the output ranking as data abstractions. In order to refine the solution further, we must decide how to store the predecessor counts, the successors of each object, the bag, and the output ranking. These are data structure decisions. They should be based on the kinds of operations to be performed in tasks 1 through 5. First we functionally modularize the solution.
1. read(n);
2. a. predinitialization(n,count);
b. succinitialization(n,successor);
3. while nextpair(i,j)
a. increase(j,count);
b. insert(i,j,successor)
4. baginitialization(bag,n,count);
5. while not emptybag(bag)
a. remove(bag,obj);
b. update(successor,obj,bag,count)
Every operation performed in tasks 1 through 5 that involves the bag, any of the n predecessor counts or collections of successors, or the output ranking has been implemented by a corresponding function. Note the use of a prefix to designate the structure involved in some of these operations. When written in this form, the program is independent of the specific details of implementation of each of these structures. This means that even if changes in the data structure implementations are ultimately adopted, this version of the solution will never need to be modified.
The next step is to decide on specific data structures for implementation of the data abstractions. This choice must be based on the functions that operate on the data structures. These functions include predinitialization,succinitialization, increase, decrease, iszero, insert, baginitialization, emptybag, and remove.
At some future time a decision may be made to change the implementation of any data abstraction. This requires finding all declarations and definitions of the data structures and functions involved and replacing them with the new versions.This modification may be made more easily and more reliably when the originals have been localized in the program. Such localization is called encapsulation. Not all high-level languages provide appropriate tools for achieving the same degree of encapsulation. In the ideal final program the data abstractions are defined in precisely one place; even more important, no operations are allowed on the corresponding data structures except those specified by the functions of the data abstraction. In the implementation above, this means, for example, that for the bag only the baginitialization, emptybag, remove, plus any other operations we take as basic to the bag will appear together. This makes it easier to determine which operations may be affected by a new implementation of the bag.The greater the encapsulation and modularization, the more expeditious the process of achieving correct modifications and adaptations. How to do this in C was discussed in Chapter 5.
We are actually in a position now to make a decision on the implementations for count, successor, and bag. The programmer does not know, in advance, the order in which objects will be output. In task 5b of the better refinement, after an object is output, its successors must be accessed and their predecessor counts updated. This means that the predecessor counts and the collections of successors must be accessed in arbitrary order. Because arrays support random access to their entries, we choose to store the predecessor counts in an array count and pointers to each collection of successors in an array succ. Count[i] and succ [i] will then contain, respectively, the predecessor count and a pointer to the successors of object i. This allows the predecessor count and collection of successors of any object to be selected, taking constant time. Since we shall need to access the collection of successors of objects, we define access_succ(i,succ) as a basic operation that returns a pointer to the collection of successors of object i.
There are n collections of successors, one for each object. These may be stored separately or may share storage. This choice has important ramifications, which will be discussed later. For now, it is best to share storage and to implement each collection of successors as a list of records. The records consist of two integer fields, succobj, containing a successor object, and link, containing a pointer to the next list record. Either dynamic memory or an array may be used to store the records. Selecting the array for storage means the programmer must manage its allocation himself or herself. Dynamic memory is probably a more natural choice, but an array of records is used to illustrate its simple management in this case and to make the later discussion comparing shared or separate storage for the list records more concrete. Lists will be the array for record storage, and a variable t will keep track of the next available record in lists for task 3b. Since only insertions will be made into the lists, the entries of lists will be allocated one after another as needed, starting with the first. Thus t must be initialized correctly.
The apparent choice for the output ranking is an integer array rank, with a variable next specifying where the next output object is to be placed in the rank array. For convenience, we use the record ranking with the two fields rank and next.
The bag could be implemented similarly, in an array with bag pointing to the next available element for a new bag entry. When an object is to be removed from the bag, we can store its value in obj and then decrease bag by 1. Thus an object can be added or removed from the bag in constant time. This implementation is permissible because objects may be selected from the bag in any order. However, implementing the bag as in Figure 11.5 affords an advantage. By allowing the bag and the output ranking to share storage, it saves time. However, this selection is made primarily to emphasize a point to be made later about the independence of modules. In order to simplify the example, only the array entries starting with 1 are used. As you know, in C they start with zero; 0th array positions will not be used in this example so that ranking and array positions will be identical.
The X's represent nine objects placed in the rank array. Next, pointing to position 6, indicates that the next object to be selected from the bag will be the one in rank[next],rank[6] in this case. Bag, pointing to 10, indicates that when a successor is to be added to the bag, it should be placed in rank[bag],rank[10] in this case. In other words, the bag contains all objects in rank between next and bag-1.
The bag is initialized by traversing the count array and placing any object with zero count into the location of the rank array to which bag points. Bag, of course, must then be updated by 1 to move its pointer down. Bag must initially be 1, and next must initially be 1. Objects are then output in the order in which they are placed into the bag, easing processing and keeping the time constant for addition or removal of an object. Each time an object is selected, next must be increased by 1 to move it down. The bag is empty when next equals bag.
Before proceeding, phase I is illustrated by applying it to Example 11.6. For this example, count, succ, t, and list would appear as in Figure 11.6, after the first eight pairs have been input. Figure 11.7 graphically depicts the successor lists.
At the start of phase I, no information was processed yet on predecessors or successors for any object. The first pair, 7 3, contains the information that 3 has one more predecessor than was known, and that 7 has one more successor than was known, namely 3. One must be added to the count for 3, and 3 to the list of successors of 7, and so on for the other seven pairs.
The detailed processing of an input pair is illustrated for the last pair of this example. It is the ninth pair, 7 6. To update the count for 6, add 1 to count[6]. To create a record to contain the successor 6, place 6 into lists[9].succobj and add this new record to the current successor list for 7 by changing two pointers. First, copy the pointer from succ[7], the head of the list to which the new record is to be added, into the link field of the new record lists[9].link. Then place a pointer into succ[7] so that it points to the new record. In this case, 9 is placed into succ[7]. Since successors need not be kept in any special order, always adding records at the front of successor lists saves processing time. Adding the record anywhere else on the list would require traversal time from the head of the list to the insertion place. T must be incremented by 1 so that it points to the next available record in lists. The final situation after all nine input pairs have been read and processed is shown in Figures 11.8 and 11.9. An X indicates a null pointer.
We are now ready to consider the actual implementations for the functions of the data abstractions. Following is the code that might be used for those functions whose implementation may not be apparent.
increase
decrease
iszero
avail
insert
succinitialization
emptybag
remove
Note that avail must correctly initialize and update t.
Task 5b of the better (or "bag") refinement of the algorithm could be done by writing the procedure update from scratch. Instead, it is done here using a tool that is available, the traverse procedure of Chapter 3. First, traverse is modified by adding bag and count as additional parameters of both traverse and process, and changing its name to update.
Process, called by update, must now be implemented so that update does its job. Its code is
A complete program using topsort follows. Notice that topsort has two parameters. It is the same as our version, except it copies the rank field of ranking into the output array as a last step.
Because of the implementation, some functions must have access to specific variables. C requires these variables to be either passed as pointers or declared as global. For example, process must have access to rank, and emptybag to next. Incidentally, as written, topsort does not depend on the medium assumed for the input pairs. Normally, we want programs to be independent of the form of the input. This has been accomplished here for the pairs by using the function nextpair(i,j), which inputs the next pair and returns true if it is a nonsentinel pair. The program uses 0 0 as the sentinel pair.
Note that the ranking and bag implementations are not independent. Thus, if it is desirable to change the implementation of one, the other is also affected. As written, the bag acts as a stack, but it may be important to pick the entry to be removed from the bag more selectively. One way to do this is to implement the bag as a priority queue. In any case, to make ranking and bag independent requires changing their declarations, definitions, and basic operations.

Figure 11.5 Data Structure Implementation of Bag and Output-Ranking Data Abstractions
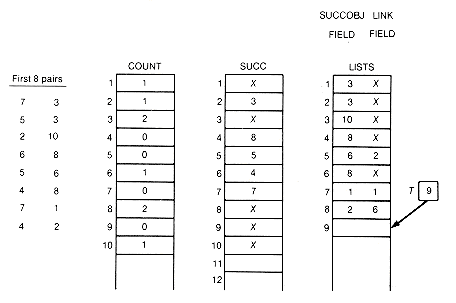
Figure 11.6 Data Structures Involved in Phase I after Input of First Eight Pairs
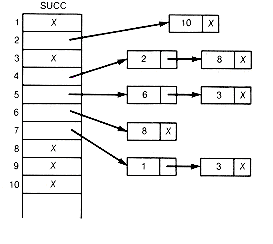
Figure 11.7 Graphic Depiction of Successor Lists

Figure 11.8 Data Structures of Figure11.7 after Processing Last Input Pair of Phase I
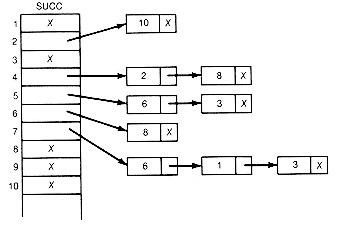
Figure 11.9 Graphic Depiction of Successor Lists of Figure 11.8
count[j] = count[j] + 1;
count[i] = count[i] - 1;
return(count[i] == 0);
static int t=0;
t++;
return(t);
pointer = avail();
setinfo(pointer,j);
setlink(pointer,succ[i]);
succ[i] = pointer;
for (i=1;i<=n;i++)
succ[i] = setnull();
emptybag =(bag == ranking.next);
*pobj = ranking.rank[ranking.next];
ranking.next = ranking.next + 1;
currentsucc = info(recordpointer);
decrease(currentsucc,count);
if(iszero(currentsucc,count))
{ranking.rank[*pbag] = currentsucc;
*pbag = *pbag + 1;
}
#defineLIMIT 21
typedef int outputarray[LIMIT];
main()
/* Reads the number of objects n and the input pairs
specifying a partial order on the objects, and prints
a topological sort of the n objects. Each pair should
not occur more than once in the input and n should
not exceed twenty. The sentinel pair is 0 0.
*/
{int n,i;
outputarray topologicalsort;
topsort(&n,topologicalsort);
printf("\n A TOPOLOGICAL SORT IS");for (i=1;i>=n;1++)
printf("\n %d",topologicalsort[i]);}
typedef int countcollection[LIMIT];
predinitialization(n,count)
/* Initializes all n counts to zero. */
int n;
countcollection count;
{int i;
for (i=1;i<=n;i++)
count[i] = 0;
}
increase(j,count)
/* Increases the jth count by one. */
int j;
countcollection count;
{count[j] = count[j] + 1;
}
decrease(j,count)
/* Decreases the jth count by one. */
int j;
countcollection count;
{count[j] = count[j] - 1;
}
iszero(i,count)
/* Returns true only if the ith count is zero. */
int i;
countcollection count;
{return(count[i] == 0);
}
#define RECORDLIMIT 191
/* RECORDLIMIT should be at least
(((LIMIT-1)*(LIMIT-2))/2)+1
*/
#define NULL - 1
typedef int listpointer;
typedef struct
{int succobj;
listpointer link;
}listrecords,recordsarray[RECORDLIMIT];
recordsarray lists;
listpointer setnull()
/* Returns a null pointer. */
{return(NULL);
}
anotherrecord(recordpointer)
/* Returns true only if recordpointer
points to a record.
*/
listpointer recordpointer;
{return(recordpointer != NULL);
}
info(pointer)
/* Returns the contents of the succobj field
of the record pointed to by pointer.
*/
listpointer pointer;
{return(lists[pointer].succobj);
}
listpointer next(pointer)
/* Returns the link field value of
the record pointed to by pointer.
*/
listpointer recordpointer;
{return(lists[recordpointer].link);
}
setinfo(pointer,value)
/* Copies value into the succobj field
of the record pointed to by pointer.
*/
listpointer pointer;
int value;
{lists[pointer].succobj = value;
}
setlink(pointer1,pointer2)
/* Copies pointer 2 into the link field
of the record pointed to by pointer 1.
*/
listpointer pointer1,pointer2;
{lists[pointer 1].link = pointer2;
}
listpointer avail()
/* Returns a pointer to storage allocated
for a list record.
*/
{static int t=0;
t++;
return(t);
}
typedef listpointer succ_collection[LIMIT];
insert(i,j,succ)
/* Add j into the ith collection in succ. */
int i,j;
succ_collection succ;
{listpointer pointer,avail();
pointer = avail();
setinfo(pointer,j);
setlink(pointer,succ[i]);
succ[i] = pointer;
}
succinitialization(n,succ)
/* Initializes all n collections of succ to empty. */
int n;
succ_collection succ;
{int i;
listpointer setnull();
for (i=1;i<=n;i++)
succ[i] = setnull();
}
listpointer access_succ(i,succ)
/* Returns a pointer to the i collection in succ. */
int i;
succ_collection succ;
{return(succ[i]);
}
typedef struct
{outputarray rank;
int next;
}rankingrecord;
rankingrecord ranking;
1 allocates storage for ranking
copy(n,topologicalsort,ranking)
/* Copies the rank field of ranking
into topologicalsort.
*/
int n;
outputarray topologicalsort;
rankingrecord ranking;
{int i;
for (i=1;i<=n;i++)
topologicalsort[i] = ranking.rank[i];
}
typedef int bagcollection;
baginitialization(pbag,n,count)
/* Initializes the bag so it contains
only objects whose counts are zero.
*/
bagcollection *pbag;
int n;
countcollection count;
{int i;
ranking.next = 1;
*pbag = 1;
for(i=1;i<=n;i++)
if(iszero(i,count))
{ranking.rank[*pbag] = i;
*pbag = *pbag + 1;
}
}
emptybag(bag)
/* Returns true only if bag is empty. */
bagcollection bag;
{return(bag == ranking.next);
}
remove(pbag,pobj)
/* Sets obj to an object to be removed
from bag, and removes it.
*/
bagcollection *pbag;
int *pobj;
{*pobj = ranking.rank[ranking.next];
ranking.next = ranking.next + 1;
}
process(listname,recordpointer,pbag,count)
/* Decreases the count of the successor pointed
to by recordpointer and adds it to the bag if
its count has become zero.
*/
listpointer listname,recordpointer;
bagcollection *pbag;
countcollection count;
{int currentsucc;
currentsucc = info(recordpointer);
decrease(currentsucc,count);
if (iszero(currentsucc,count))
{ranking.rank[*pbag] = currentsucc;
*pbag = *pbag + 1;
}
}
topsort(pn,topologicalsort)
/* Inputs the number of objects n and the
partial order and generates a solution in
topologicalsort.
*/
int *pn;
outputarray topologicalsort;
{countcollection count;
succ_collection succ;
bagcollection bag;
int i,j,obj;
printf("\n enter n between 1 and %d\n",LIMIT-1);scanf("%d",pn);predinitialization(*pn,count);
succinitialization(*pn,succ);
while (nextpair(&i,&j))
{increase(j,count);
insert(i,j,succ);
{baginitialization(&bag,*pn,count);
while(!emptybag(bag))
{remove(&bag,&obj);
update(succ,obj,&bag,count);
}
copy(*pn,topologicalsort,ranking);
}
nextpair(pi,pj)
int*pi,*pj;
/* Input the next pair and return true
only if it was not the sentinel pair.
*/
{print("\n enter a pair \n");scanf("%d %d",pi,pj);return(!((*pi == 0) && (*pj == 0)));
}
update(succ,obj,pbag,count)
/* Update the counts of all successors of obj
and place any whose counts become zero
into bag.
*/
succ_collection succ;
int obj;
bagcollection *pbag;
countcollection count;
{listpointer listname,recordpointer,access_succ();
listname = access_succ(obj,succ);
recordpointer = listname;
while(anotherrecord(recordpointer))
{process(listname,recordpointer,pbag,count);
recordpointer = next(recordpointer);
}
}